Hello there!! I am having an issue that I really don’t know how to solve and I have been trying for weeks. I have a binary classification task with two labels “Label 1” and “Label 2”. Model training conditions described in the following topics.
- I am using pre-trained resnet (already tried several ones, resnet18, resnet34, resnet50, resnet101). Also already tried densenet121 and the results are more a less the same.
- Image size: to 224x224
- My dataset is composed of 715 train images and 174 validation images. With data augmentation (random crop, random flip and colour jitter) the dataset size increases to 1430 training images. I already double and triple checked and I don’t have wrong labels or mix data between train and validation sets.
- Tried also two different loss functions: CrossEntropyLoss and SigmoidFocalLoss.
- The learning rate was varied from 0.01 to 0.0001.
- The optimizer I am using is Adam, but I also already tested SGD.
- The batch size used was 5, 16 or 32.
- Also, I tried to add some regularization, including the dropout and weight decay.
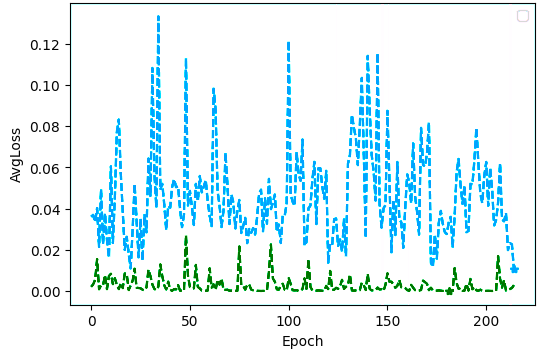
However, the weird behaviour still happens, which is this one I show in the image. I have a very unstable validation loss that usually doesn’t show a tendency of decreasing, it just decreases randomly on some of the epochs, it seems almost like the model is not learning. These types of curves are not really what is expected. I am not even sure if we can call this overfitting. However, the accuracy is not that bad, on a set of 100 images, usually, it has an accuracy of more a less 85% or more, but at the same time the images that are failing are not corner cases and it was not expected that they would fail.
Does anyone have any ideas about what I could do to improve the model or does anyone even knows the reason why this could be happening?
Thank you in advance.