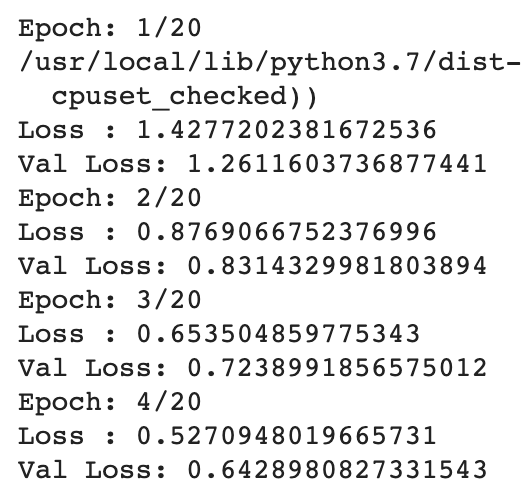
I’m training VGG16 model from scratch on CIFAR10 dataset. The validation loss diverges from the start of the training.
I have tried with Adam optimizer as well as SGD optimizer. I cannot figure out what it is that I am doing incorrectly. Please point me in the right direction.
# Importing Dependencies
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.datasets import CIFAR10
from torchvision import transforms
from torch.utils.data import DataLoader
from tqdm import tqdm
from datetime import datetime
# Defining model
arch = [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
class VGGNet(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.in_channels = in_channels
self.conv_layers = self.create_conv_layers(arch)
self.fcs = nn.Sequential(
nn.Linear(in_features=512*1*1, out_features=4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.conv_layers(x)
# print(x.shape)
x = x.reshape(x.shape[0], -1)
x = self.fcs(x)
return x
def create_conv_layers(self, arch):
layers = []
in_channels = self.in_channels
for x in arch:
if type(x) == int:
out_channels = x
layers += [nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(x),
nn.ReLU(),
]
in_channels = x
elif x =='M':
layers += [nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))]
return nn.Sequential(*layers)
# Hyperparameters and settings
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
TRAIN_BATCH_SIZE = 64
VAL_BATCH_SIZE = 16
EPOCHS = 50
train_data = CIFAR10(root=".", train=True,
transform=transforms.Compose([transforms.ToTensor()]), download=True)
# print(len(train_data))
val_data = CIFAR10(root=".", train=False,
transform=transforms.Compose([transforms.ToTensor()]), download=True)
# print(len(val_data))
train_loader = DataLoader(train_data, batch_size=TRAIN_BATCH_SIZE, shuffle=True, num_workers=8)
val_loader = DataLoader(val_data, batch_size=VAL_BATCH_SIZE, shuffle=True, num_workers=8)
# print(len(train_loader))
# print(len(val_loader))
num_train_batches = int(len(train_data)/TRAIN_BATCH_SIZE)
num_val_batches = int(len(val_data)/VAL_BATCH_SIZE)
# Training and Val Loop
model = VGGNet(3, 10).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# optim = torch.optim.Adam(model.parameters(), lr=0.01)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=10, verbose=True)
# save_path = os.path.join(r"trained_models", f'{datetime.now().strftime("%m%d_%H%M%S")}.pth')
def train_val():
for epoch in range(1, EPOCHS+1):
print(f"Epoch: {epoch}/20")
model.train()
total_loss = 0
for data in train_loader:
image, target = data[0], data[1]
image, target = image.to(device), target.to(device)
optimizer.zero_grad()
output = model(image)
loss = criterion(output, target)
total_loss += loss.item()
loss.backward()
optimizer.step()
print(f"Loss : {total_loss / num_train_batches}")
save_path = os.path.join(r"trained_models", f'{datetime.now().strftime("%m%d_%H%M%S")}_{epoch}.pth')
if epoch % 5 == 0:
torch.save(model.state_dict(), save_path)
with torch.no_grad():
model.eval()
total_val_loss = 0
for data in val_loader:
image, target = data[0], data[1]
image, target = image.to(device), target.to(device)
output = model(image)
val_loss = criterion(output, target)
total_val_loss += val_loss
total_val_loss = total_val_loss/num_val_batches
print(f"Val Loss: {total_val_loss}")
scheduler.step(total_val_loss)
Output is :
Epoch: 1/20 Loss : 1.3286100650795292 Val Loss: 1.3787670135498047
> Epoch: 2/20 Loss : 0.822020811685832 Val Loss: 0.948610246181488
> Epoch: 3/20 Loss : 0.6018326392113476 Val Loss: 0.9581698775291443
> Epoch: 4/20 Loss : 0.47134833609764004 Val Loss: 1.2446043491363525
> Epoch: 5/20 Loss : 0.35625831704114524 Val Loss: 0.8038020730018616
> Epoch: 6/20 Loss : 0.27602518926566605 Val Loss: 0.6090452075004578
> Epoch: 7/20 Loss : 0.21279048924686128 Val Loss: 0.6626076102256775
> Epoch: 8/20 Loss : 0.16782210255280214 Val Loss: 0.6386368870735168
> Epoch: 9/20 Loss : 0.12904227719518205 Val Loss: 0.8135524988174438
> Epoch: 10/20 Loss : 0.10961572862077902 Val Loss: 0.727300226688385
> Epoch: 11/20 Loss : 0.08377284912137456 Val Loss: 0.7346469163894653
> Epoch: 12/20 Loss : 0.07044737199237916 Val Loss: 0.8241418600082397
> Epoch: 13/20 Loss : 0.06040401630707726 Val Loss: 0.8411757349967957
> Epoch: 14/20 Loss : 0.05157513573171604 Val Loss: 0.9980310201644897
> Epoch: 15/20 Loss : 0.04703645325243019 Val Loss: 0.7441162467002869
> Epoch: 16/20 Loss : 0.039386494244257594 Val Loss: 0.7185537219047546
> Epoch: 17/20 Loss : 0.0361507039006692 Val Loss: 0.7251362800598145
> Epoch 17: reducing learning rate of group 0 to 1.0000e-03.
> Epoch: 18/20 Loss : 0.010131187833331622 Val Loss: 0.6911444067955017
> Epoch: 19/20 Loss : 0.004273188020082817 Val Loss: 0.6758599877357483
> Epoch: 20/20 Loss : 0.0023282255553611917 Val Loss: 0.6790934801101685
I trained it till 50 epochs but the val_loss was still seeing almost same numbers on losses.
- Is there anything wrong with my model?
- Is there anything wrong in my training or validation loop?
- What can I try to make it converge?
Thank You