Hi everyone,
I’ve been trying to implement a (conditional) feature generator GAN described in the paper “Imagine it for me: Generative Adversarial Approach for Zero-Shot Learning from Noisy Texts”, arxiv link: [1712.01381] A Generative Adversarial Approach for Zero-Shot Learning from Noisy Texts
For the generator’s loss, they propose a “Visual Pivot” regularization term as shown below:
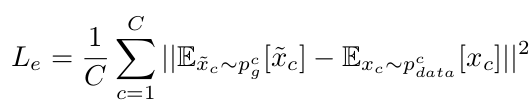
To do that, you need to compute the difference between the means of the real and synthesized features per class. Computing the means of the generated features is described below:
https://drive.google.com/open?id=1TrayxuI9pkWzq8Kpj0iQZyrJacMunkBg
Their presented pseudo-code for updating the parameters of the generator:
https://drive.google.com/open?id=17j3z5G-YgQK5ip8ZPC1WZNHoaaD5GRpy
And the way I’ve implemented it (only the part for updating the generator’s parameters):
self.net_g.zero_grad()
rnd_noise = Variable(torch.randn(batch_size, self.args.n_z))
if self.cuda:
rnd_noise = rnd_noise.cuda()
fake_samples = self.net_g(rnd_noise, cls_tfidf)
out_g_fake_s, out_g_fake_cls = self.net_d(fake_samples)
loss_g_fake_cls = self.ce_loss(out_g_fake_cls, cls)
# visual pivot regularization term
cls_list = list(cls.cpu().data.numpy()) # cls: corresponding classes of the features in the current mini-batch
cls_set = set(cls_list) # set of all available classes in the current mini-batch
# initialize the means per class with 0
means_fake_set = {c: 0 for c in cls_set}
means_real_set = {c: 0 for c in cls_set}
counts_set = {c: 0 for c in cls_set}
# compute the mean for all classes
for t in range(batch_size):
means_fake_set[cls_list[t]] += fake_samples[t]
means_real_set[cls_list[t]] += feats[t]
counts_set[cls_list[t]] += 1
l_reg = 0
for c in cls_set:
means_fake_set[c] = means_fake_set[c]/counts_set[c]
means_real_set[c] = means_real_set[c]/counts_set[c]
l_reg += torch.norm(means_fake_set[c] - means_real_set[c])**2
l_reg = self.lambda_vp * (1.0 / len(cls_set)) * l_reg
# compute the total loss
loss_g = (-out_g_fake_s.mean() + loss_g_fake_cls) + l_reg # Loss_G = L_G + L_reg
loss_g.backward()
self.optimizer_g.step()
It doesn’t work and it gives very large losses for either small or large lambda_vps. Is there any fundamental issue with the way I’m trying to compute the means per class?