Hi,
Currently, I am trying to apply a ViT transformer as a backbone for my image segmentation.
Using a pre-trained ViT, I obtain the following summary for my images:
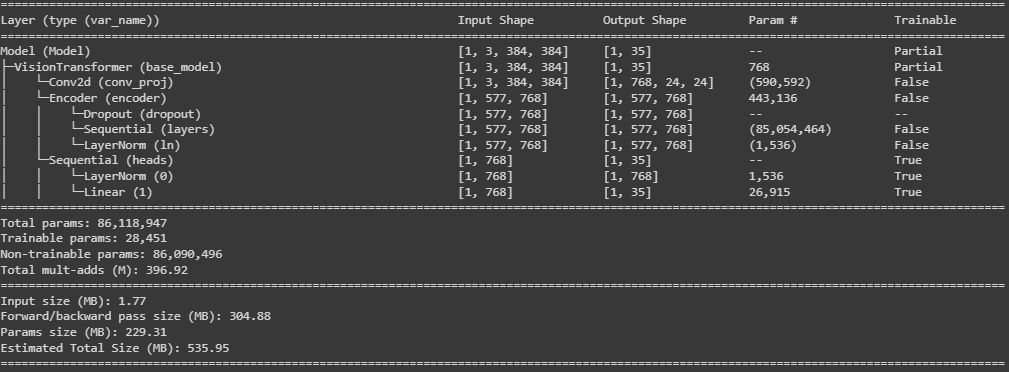
Of course, as one can see, I transformed the output to be of size [1,35] and hence being a classification procedure for each image. Therefore, I would like to transform the last output of the encoder (ViT, either of size [1,35] or the standard [1,1000] size) into the following shape of [1,num_classes,384,384]. This is compatible with an image segmentation task.
Reading several papers online (e.g. https://arxiv.org/pdf/2105.05633v3.pdf), I find some interesting observations, but they do not clearly indicate how to address such problems in terms of code. Therefore, I was wondering if somebody could point me in the right direction to scale the image back to its original format to perform image segmentation.
Thanks!
Dirk