I tried to optimize the process of derivative calculation in PyTorch using vmap. Here’s my original code:
dx_over_dt = torch.zeros_like(new_confs)
d2x_over_dt2 = torch.zeros_like(new_confs)
grad_mask = torch.ones(ts.shape[0]).to(device)
for i in range(num_atoms):
for j in range(3):
dx_over_dt[:, i, j] = torch.autograd.grad(
new_confs[:, i, j], ts, create_graph=True,
retain_graph=True, grad_outputs=grad_mask
)[0]
d2x_over_dt2[:, i, j] = torch.autograd.grad(
dx_over_dt[:, i, j], ts, create_graph=True,
grad_outputs=grad_mask
)[0]
new_confs is the output of my model, and ts is one of the inputs to my model with ts.requires_grad = True. Then I modified the code to:
batch_size = ts.shape[0]
new_confs = new_confs.reshape(batch_size, -1).contiguous()
grad_mask = torch.eye(new_confs.shape[-1]).to(new_confs)
grad_mask = grad_mask.repeat(batch_size, 1, 1)
dx_over_dt = vmap(lambda v: torch.autograd.grad(
new_confs, ts, create_graph=True,
retain_graph=True, grad_outputs=v
)[0], in_dims=1, out_dims=1)(grad_mask)
d2x_over_dt2 = vmap(lambda v: torch.autograd.grad(
dx_over_dt, ts, create_graph=True, grad_outputs=v
)[0], in_dims=1, out_dims=1)(grad_mask)
dx_over_dt = dx_over_dt.reshape(batch_size, -1, 3)
d2x_over_dt2 = d2x_over_dt2.reshape(batch_size, -1, 3)
new_confs = new_confs.reshape(batch_size, -1, 3)
However, no matter how I adjust the model structure and format, this code will definitely throw an error on the third call (the code successfully runs for two batches) with the following error:
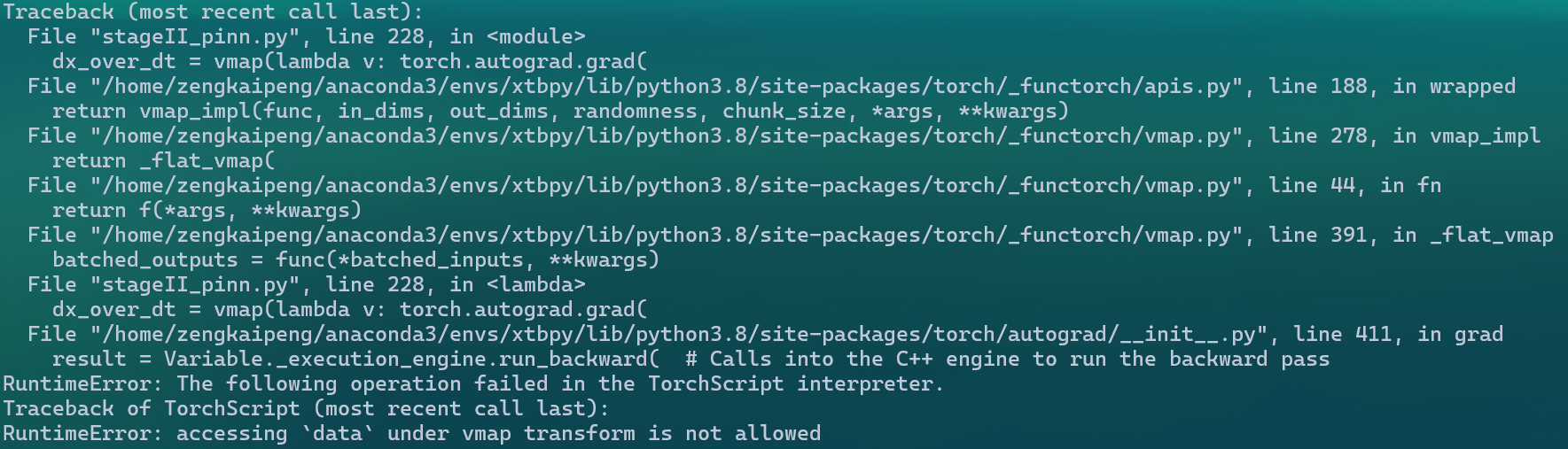
I would like to know why this happens. Is this a bug in vmap, or is there an alternative way to write this code?