I have found this question posted on this forum for the multiple times with no working answer.
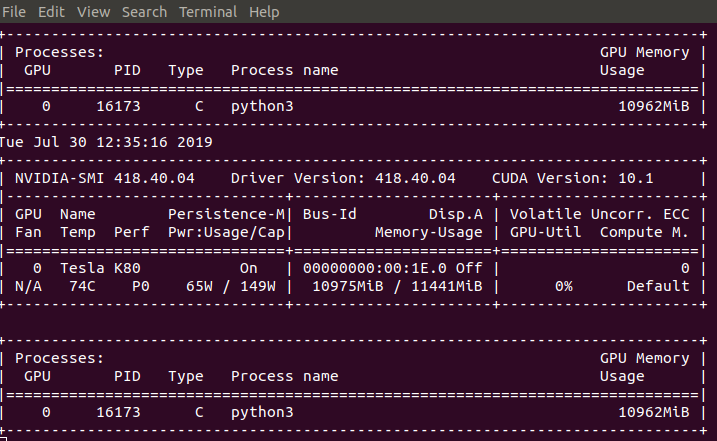
I am trying to train a SegNet on satellite images using single GPU (Nvidia Tesla-k80 12GB). Memory-Usage is high but the volatile GPU-Util is 0%.
In the DataLoader, I have tried increasing the
num_workers, setting the
pin_memory= True, and
removed all the preprocessing like Data Augmentation, Caching etc… but the problem is still persistent. The code works just fine if I change the dataset.
Any help will be highly appreciated.
What did you change regarding the dataset?
If the samples are smaller or you can preload the other dataset completely, it points to a data loading bottleneck using your current dataset.
Hi Patrick,
What are the general guidelines in order to make optimal GPU and CPU usage. I faced the same problem mentioned here when I tried to run the 'training classifier" notebook tutorial. When I changed the batch size nothing changed in the GPU usage (~600-700MB).
The setup:
CIFAR10 dataset
2 X 1080 ti (nvidia)
8 processors 32GB RAM memory
Yes, the other dataset have smaller samples (images with low spatial resolution).
How can I avoid this bottleneck situation?
@rwightman shared some insights on data bottlenecks here.
CC @Aviv_Shamsian
Hi @ptrblck
Thank you for your quick response!
Can you please address to my specific problem? I read the comment you tagged me in but I have done all is written there. I’m using the Pytorch Dataloader (without any unnecessary for loops). How can I be sure what is the main cause of this problem? When I use htop in terminal all the six processors assigned to the mission are loaded with work but the GPU stays in ~600-700MB capacity regardless to the batch size (which increased to 2048 at the most). This is the reason why I suspect that the preprocess part is the bottleneck in this example. Just to mention no augmentations where preformed only reading, normalizing and converting to tensor.
Hi @ptrblck Thanks for you response. I realized that the sample size was very large and took so long to load, So I tried cashing the data, it takes more memory which I can afford however once the data was cached, Volatile GPU-Util reached maximum.