Hi everyone,
I’m struggling with a very very high memory consumption with a custom Module Linear that you can find here:
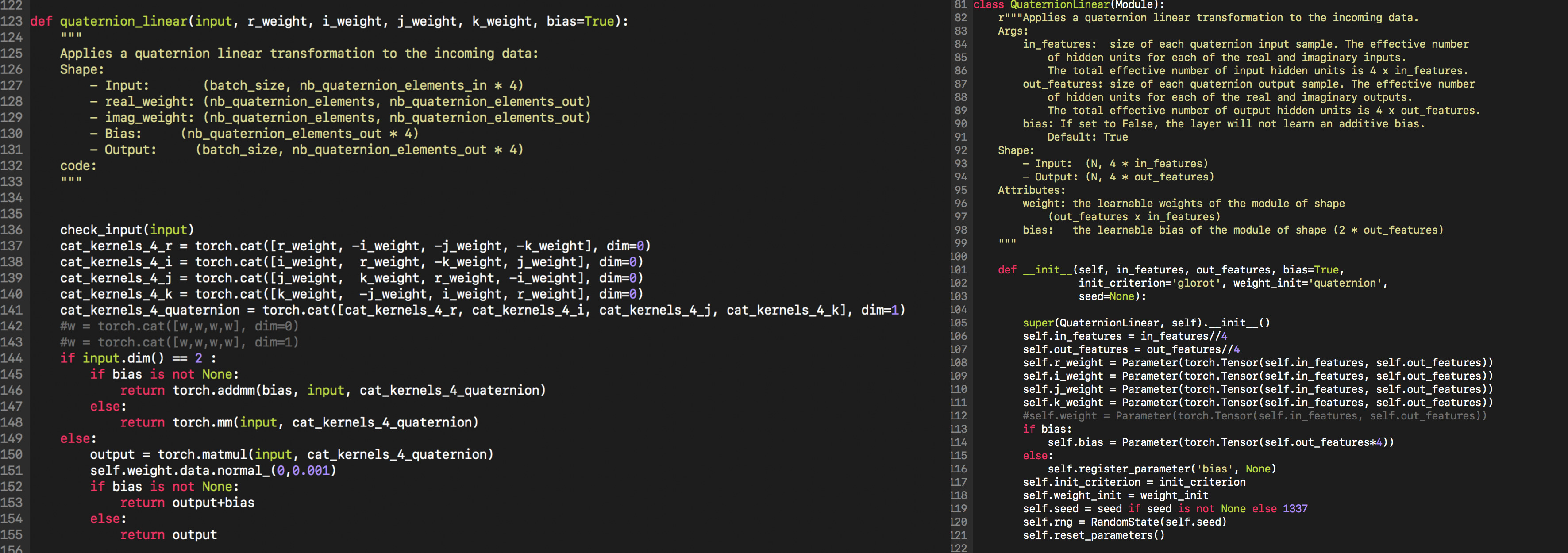
If I switch the w_r,w_i,w_j to a simple w and don’t perform any concatenation (actually it’s just a nn.linear), then the consumption is normal (equal to a nn.Linear, 6Go on 12Go) but when I use torch.concat, then OOM (12Go +). Is it normal that just a torch.cat operation blows the allocated memory ?
Thanks you !