I am trying to encode documents sentence-wise with a huggingface transformer module. I’m using the very small google/bert_uncased_L-2_H-128_A-2 pretrained model with the following code:
def pre_encode_wikipedia(model, tokenizer, device, save_path):
document_data_list = []
for iteration, document in enumerate(wikipedia_small['text']):
torch.cuda.empty_cache()
sentence_embeds_per_doc = [torch.randn(128)]
attention_mask_per_doc = [1]
special_tokens_per_doc = [1]
doc_split = nltk.sent_tokenize(document)
doc_tokenized = tokenizer.batch_encode_plus(doc_split[:512], padding='longest', truncation=True, max_length=512, return_tensors='pt')
for key, value in doc_tokenized.items():
doc_tokenized[key] = doc_tokenized[key].to(device)
with torch.no_grad():
doc_encoded = model(**doc_tokenized)
for sentence in doc_encoded['last_hidden_state']:
cpu_sentence = sentence[0].to('cpu')
sentence_embeds_per_doc.append(cpu_sentence)
attention_mask_per_doc.append(1)
special_tokens_per_doc.append(0)
sentence_embeds = torch.stack(sentence_embeds_per_doc)
attention_mask = torch.FloatTensor(attention_mask_per_doc)
special_tokens_mask = torch.FloatTensor(special_tokens_per_doc)
document_data = torch.utils.data.TensorDataset(*[sentence_embeds, attention_mask, special_tokens_mask])
torch.save(document_data, f'{save_path}{time.strftime("%Y%m%d-%H%M%S")}{iteration}.pt')
print(f"Document at {iteration} encoded and saved.")
After about a few hundred to a couple thousand iterations on my local GTX 1060 3GB I get an error saying that my CUDA is out of memory. Running this code on Colab with more GPU RAM more iterations usually. Here’s the error:
RuntimeError: CUDA out of memory. Tried to allocate 112.00 MiB (GPU 0; 3.00 GiB total capacity; 1.95 GiB already allocated; 0 bytes free; 1.98 GiB reserved in total by PyTorch)
Note that the exact MiBs it unsuccessfully tries to allocate changes from try to try.
Things I’ve tried:
- Adding
torch.cuda.empty_cache()to the start of every iteration to clear out previously held tensors - Wrapping the model in
with torch.no_grad():to disable the computation graph - Setting
model.eval()to disable any stochastic properties that might take up memory - Sending the output straight to CPU in hopes to free up memory
- Plotting the length of the input documents to check if there were any outliers and clipping them to 512 sentences
I’m baffled as to why my memory keeps overflowing. I’ve trained several models of bigger sizes, applying all the standard practices of a training loop (optimizer.zero_grad(), etc.) I’ve never had this problem. Why does it appear during this seemingly trivial task?
I’m attaching a screenshot of my VRAM usage during an overflow, it appears to me that tensors don’t accumulate but one specific input triggers the crash which is strange because I’m clipping the long inputs.
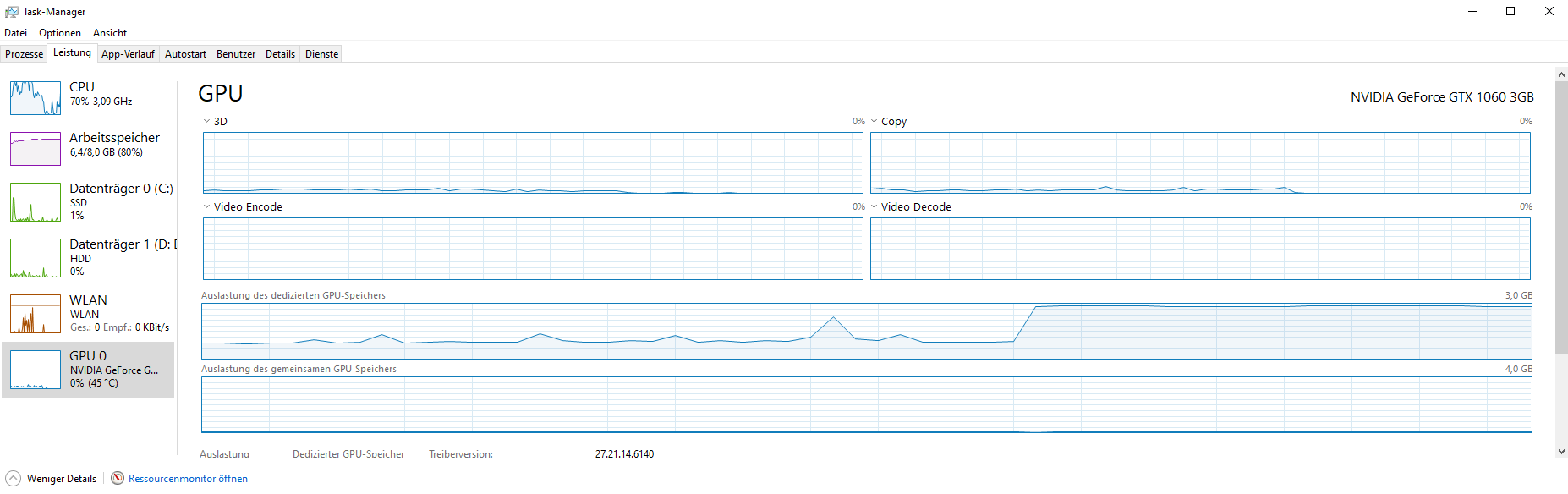
Running the program on CPU works but I still see spikes in RAM usage, but doesn’t crash because memory swapping kicks in (which doesn’t work for VRAM).