I have been working on ML-related projects for about 5 years so I am fairly experienced in this space. I am currently working on a project related to building reward models. I have run into a number of errors when trying to parallelize reward model training that have been extremely challenging to debug (as it often takes 40 mins of training before the errors are encountered) and I am looking for people who have lots of experience with PyTorch who I could pay to help me debug these issues. Are there any talented devs out there who would be interested in this or anyone with referrals? Would be greatly appreciated! I am willing to pay approx $100/hr for office hour-like support.
Here is an example of the kind of bugs I am running into.
I get the following error when trying to train my model
watchdog caught collective operation timeout and then gives an ALL REDUCE or broadcast operation
Essentially it waits more than 30 mins for the GPU to perform a particular operation
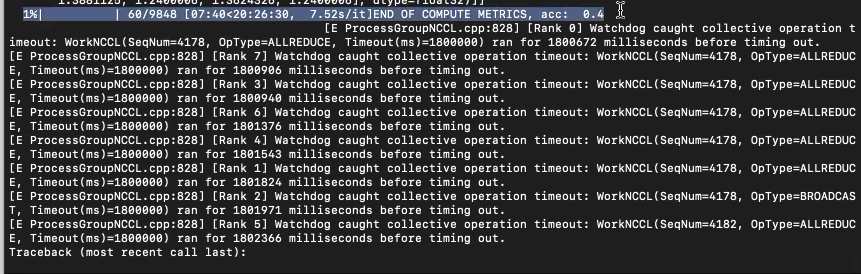
This is weird for several reasons
-
this error doesn’t work with a single GPU so it is something to do with distributed training
-
I can make this error go away with a simple change: in the forward method, instead of returning the loss that we actually compute, I just return a 0 tensor, the model doesn’t seem to freeze