Dear everyone: Is there any tutorial on using wav2vec for pre-training to extract high-dimensional speech features from datasets? thanks, best wishes
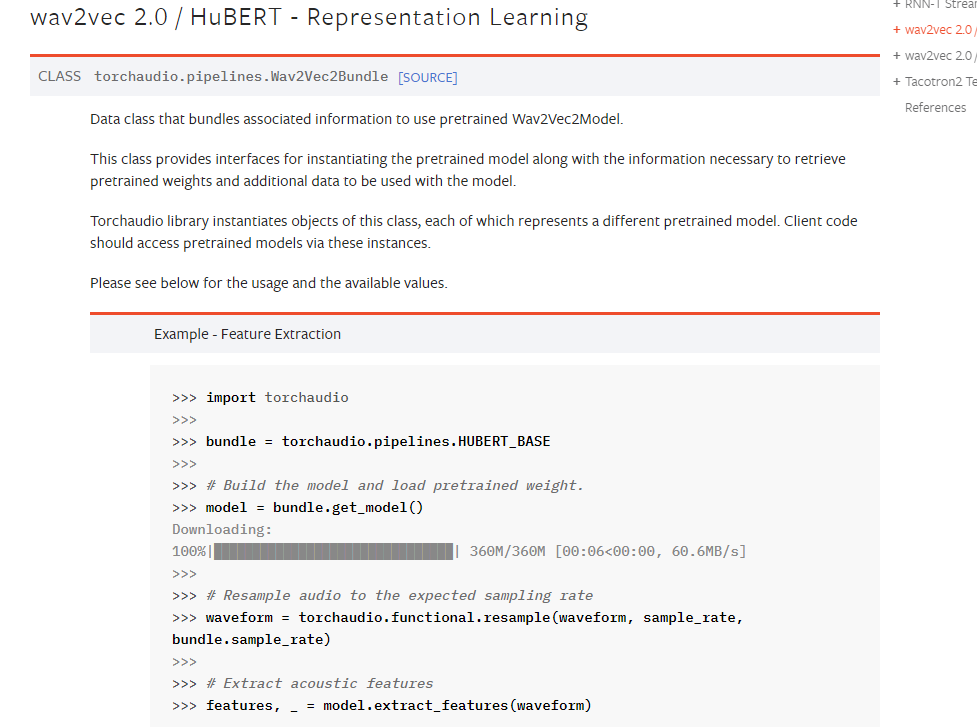
Hi @Gorgen, you can check the Wav2Vec2Bundle for extracting features by Wav2Vec2 or HuBERT pre-trained models.
Dear nateanl:
Thank you for your help.
best wishes
Hello nateanl: I am sorry to disturb you again. When I follow the HuBert tutorials to extract audio features.
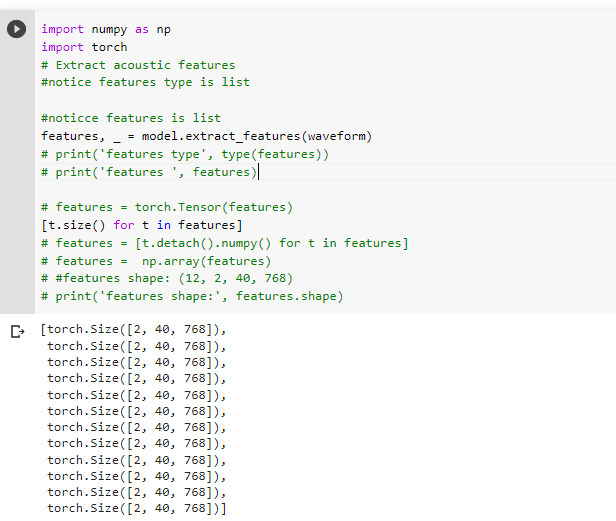
Finally, features, _ = model.extract_features(waveform) features are saved in the form of a list. There are a total of 12 elements in the list, each element is in the form of tensor, and the shape is [2, 40, 768]. So when you finally use the feature, do you stack the 12 tensor directly and shape it into [12, 2, 40, 768]. Is there a theoretical problem with doing this?
Could you please give me some suggestions?
Thanks
The 12 elements are the outputs of each transformer layer. For example, the first element is the output of the first transformer.
You can use one of the elements as the feature. The other way is weighting sum or take the average of the 12 Tensors as the feature. In either way, the shape of the final feature will be [2, 40, 768], where 2 is the batch size, 40 is the number of frames, and 768 is the feature dimension.
1 Like
I am grateful for your detailed guidance. Thanks, best wishes
sorry. I disturb you again. To be honest, I know each transformer layer are suitable for different downstream tasks. Emotion recognition, ASR, PR, and etc are needed to utilze different transformer layer(the original paper is SUPERB: Speech processing Universal PERformance Benchmark). However, they said “PR, KS, SID,IC, ER are simple tasks that are solvable with
linear downstream models. Hence, we use a frame-wise linear
transformation for PR with CTC loss; mean-pooling followed
by a linear transformation with cross-entropy loss for utterancelevel tasks (KS, SID, IC, and ER)”. I don’t know where is the frae-wise linear transformation compared to 12 transformers. Could you please give me some suggestions? Thanks
frame-wise linear transformation is just the normal torch.nn.Linear layer.
For ASR task, the process is like
waveform → transformer feature → nn.Linear → CTC loss
For KS, SID, IC, and ER task, the process is
waveform → transformer feature → mean pooling → nn.Linear → other losses
1 Like
Thank you for your detailed explanation. sorry. I’m new to deep learning. I have problem. I want to know which transformers represent the process that is suitable for KS, SID, IC and ER task (waveform → transformer feature → mean pooling → nn.Linear → other losses)? I especially want to know exactly which layer can be used forER task?
Thanks
best wishes
1 Like
It depends on your dataset. I suggest trying with different layers’ outputs and compare the performances on the development set, and choose the one with highest accuracy. Another other method is weighting sum all layers’ outputs as the input feature.
My task is about emotion recognition. I have noticed the superB benchmarr. it suggested PR, KS, SID,IC, ER are simple tasks that are solvable with
linear downstream models. Hence, we use a frame-wise linear
transformation for PR with CTC loss; mean-pooling followed
by a linear transformation with cross-entropy loss for utterancelevel tasks (KS, SID, IC, and ER). so, which layer? layer 1 or layer 2, or other? Thanks, best wishes
Thanks for providing the details. Even for emotion recognition task, if the dataset is different, the performance of the transformer features may be different. For example, the 6th layer is optimal for emotion recognition dataset A, but it may not be optimal for emotion recognition dataset B.
I suggest using layer 1, layer 6 and layer 12 to conduct three experiments, and compare the performances. So that you have a better idea of which layer is optimal for your task.
Best,
I am grateful for your detailed suggestions. Thank you for your advice.
best wishes
Please @nateanl, After weighting sum over the 12 Tensors. I would like to know the mean pooling used it is applied for frames or for features?
Hi @delo_ch, I’m not sure what the 12 Tensors are, but mean pooling is applied on the frame dimension, if the previous feature Tensor is of shape (batch, frame, feature_dim), after mean pooling the shape will be (batch, feature_dim). Thanks.
Thanks, @nateanl for your feedback. In fact, the 12 tensors are the features obtained from the 12 layers, which have the following shape (12, number_of_frames, feature_dimension) and each layer has the shape (number of frames, feature dimension), what is commonly used is to apply the average over the weights of all the layers to have a vector with the shape (1, number_of_frames, feature_dimension). When we apply the average, we set up the process of mean pooling, but I would like to know if we can use it on the feature dimension instead of the frame dimension.
applying it on feature dimension doesn’t make much sense, especially when your input has different lengths, then each feature Tensor ends up with different dimensions.
2 Likes
Yes, that is the major problem. OK, thank you @nateanl