i have been trying to quantise the WAV2VEC2_ASR_BASE_960H model using static_fx mode but getting the example input size error. not sure what size to give (sample input size is (1,54400) and sampling rate is 16k) . also can anybody help me to get the steps to static quantize the model
import torch
import torchaudio
bundle = torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H
model = bundle.get_model()
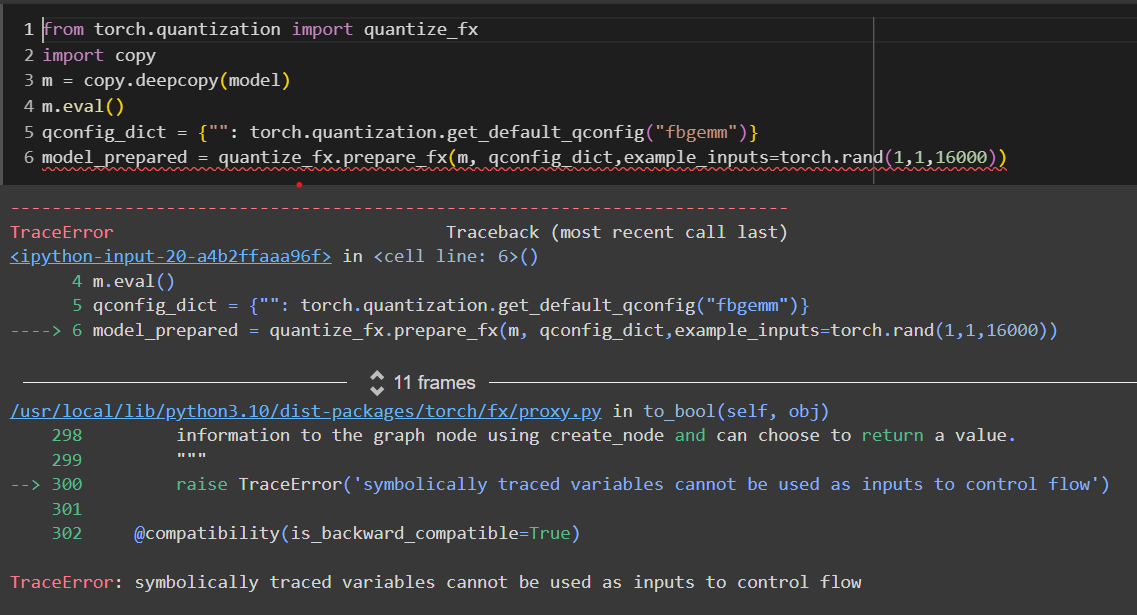
from torch.quantization import quantize_fx
import copy
m = copy.deepcopy(model)
m.eval()
qconfig_dict = {"": torch.quantization.get_default_qconfig("fbgemm")}
model_prepared = quantize_fx.prepare_fx(m, qconfig_dict,example_inputs=torch.rand(1,54400))
This doesn’t look like an example input size error, it looks like symbolic tracing error. If you don’t do quantization but do normal fx tracing does your model work?
from torch.fx import symbolic_trace
# Symbolic tracing frontend - captures the semantics of the module
symbolic_traced : torch.fx.GraphModule = symbolic_trace(model)
in that case its not a quantization issue, its a tracing issue, you can either use eager mode quantization (to remove the need for traceability) or get this model to be traceable. I’m not an expert but i think the tracing can’t do different things based on the input data so if you hardcode dtype and device in that line of the model, it may get past that point.