Dear all,
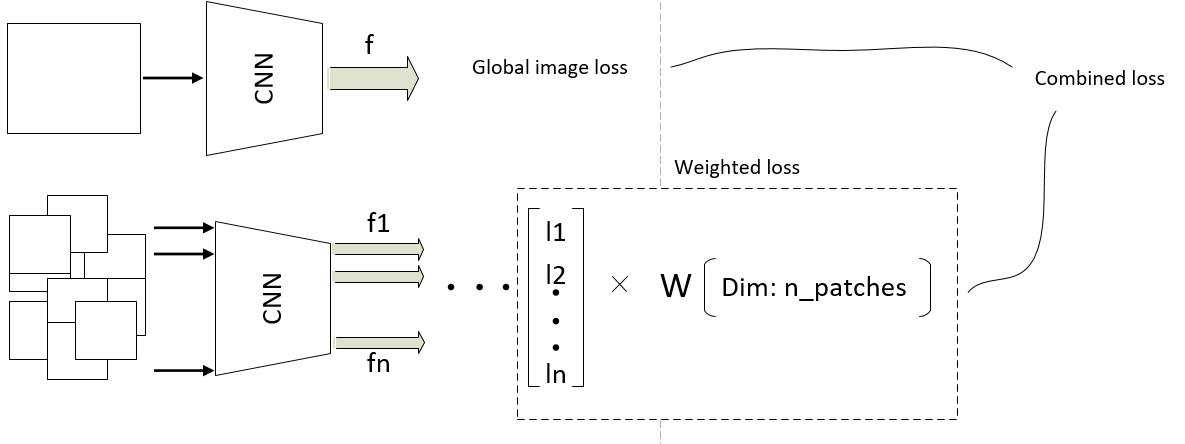
I want to ask you for some help. I am training a dual-path CNN, where one path processes the image in a holistic manner, where the other path processes the same image but patch-wise, which means I decompose N_patches from the same image, and feed all patches in a second CNN, where each single patch goes in the same CNN (sharing weights).
My idea is to make a combined loss function, where in the local processing path (from the two path model), the local losses are calculated, which means each patch corresponds to its own loss. Now my question is, how to make weighting between the local losses, where the weights are learnable during the training.
In the final stage I combine the global loss and the local loss (the local loss is then averaged).
I already trained the combined Cnn model, where in the final stage i combined the global image features and the local image features, but now i want to try to learn local losses from the local processing path.
I did something like this:
class PatchRelevantLoss(nn.Module):
def __init__(self, n_patches):
super(PatchRelevantLoss, self).__init__()
self.ce = nn.CrossEntropyLoss(reduction = 'none')
self.n_patches = n_patches
self.weights = .... nn.Parameter or something (dim: n_patches)
def forward(self, feature_matrix, labels):
loss = ()
for features, weight in zip(feature_matrix, self.weights):
loss += ((self.ce(features, labels)*weight ).mean(0), )
loss = torch.stack(loss, 0)
return loss
Shapes: feature_matrix has (n_patches, batch_size, feature_dimension)
Now the idea is to make the wieghts learnable.
Here is the basic idea on the picture.
I am new to Pytorch and i’ll be thankful for some help.
Cheers.