How to use samplers with custom datasets? I use torch to implements model including bert pretrained model for token classification (NER)
I already use weighted loss, but its not enough to train on my heavily imbalanced data
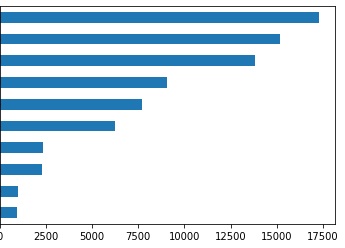 (and this is not including O tag which up to 70% of all data)
(and this is not including O tag which up to 70% of all data)
when i tried to use WeightedRandomSampler or any other sampler from torch it doesn’t work
Some custom implementations GitHub - ufoym/imbalanced-dataset-sampler: A (PyTorch) imbalanced dataset sampler for oversampling low frequent classes and undersampling high frequent ones. also raise similar errors
only DataLoader with shuffle True or False works normal for me, not any sampler
my CustomDataset looks like this
class CustomDataset(Dataset):
def __init__(self, tokenizer, sentences, labels, max_len):
self.len = len(sentences)
self.sentences = sentences
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __getitem__(self, index):
sentence = str(self.sentences[index])
inputs = self.tokenizer.encode_plus(
sentence,
None,
add_special_tokens=True,
max_length=self.max_len,
truncation=True,
padding="max_length",
# pad_to_max_length=True,
return_token_type_ids=True
)
ids = inputs['input_ids']
mask = inputs['attention_mask']
label = self.labels[index]
label.extend([0] * MAX_LEN)
label = label[:MAX_LEN]
return {
'ids': torch.tensor(ids, dtype=torch.long),
'mask': torch.tensor(mask, dtype=torch.long),
'tags': torch.tensor(label, dtype=torch.long)
}
def __len__(self):
return self.len
i use sampler
sampler = WeightedRandomSampler(weights=class_weights, replacement=True, num_samples=len(list(tag2idx.keys())))
get error
TypeError: list indices must be integers or slices, not str