Hey all. I’m trying to create a weighted sampler to do balanced sampling on my training set, and I created a sampler based off of the response here (Is there a better way to split data and deal with an unbalanced dataset?). Therefore, my code to generate a weighted sampler is very similar:
def get_weighted_sampler(dataset):
sampler = None
# Create weight array for each training sample
sorted_label_counts = dataset.label_counts.sort_index()
label_weights = sum(sorted_label_counts.iloc[:]) / np.array(sorted_label_counts.iloc[:])
sampling_weights = []
for i in range(len(dataset)):
print(i)
_, image_label = camera_catalogue_training[i]
sampling_weights.append(label_weights[image_label])
sampler = torch.utils.data.sampler.WeightedRandomSampler(sampling_weights , len(sampling_weights))
print(len(sampling_weights))
return sampler
I then tried to use this sampler with a DataLoader as follows:
I didn’t get any errors with initializing the DataLoader itself, but when I try to iterate over a batch of the DataLoader, I get a “TypeError: len() of unsized object” error. I believe this has to do specifically with this weighted sampler I’m trying to work with, because when I remove sampler and just use a normal DataLoader, I’m able to iterate and examine the contents of a batch perfectly fine. Any ideas?
What is in sampling_weights? Is it a list of numpy arrays or pd.Series?
Could you check the dytpe of one element?
Since the first approach is also throwing the same error, I guess the data is unknown.
Make sure sampling_weights is a tensor containing the weights before passing it to the Sampler.
Checking dtype of an element in sampling_weights tells me that it’s of format float64.
I also tried converting to a tensor as follows: sampling_weights2 = torch.from_numpy(np.array(sampling_weights))
And when I run dtype of an element in that, I get torch.float64. I then tried passing in this tensor, and I get the same original error.
For further context, here’s more of the error (not sure if it might be of any help or not):
for i, data in enumerate(training_loader):
File "C:\Users\ckwij\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 314, in __next__
batch = self.collate_fn([self.dataset[i] for i in indices])
File "C:\Users\ckwij\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 314, in <listcomp>
batch = self.collate_fn([self.dataset[i] for i in indices])
File "c:/Users/ckwij/Documents/--redacted--/--redacted--/Code/PyTorch/pytorch_data.py", line 53, in __getitem__
image_name = data_folder / self.labels_frame.iloc[idx, 0]
File "C:\Users\ckwij\Anaconda3\lib\site-packages\pandas\core\indexing.py", line 1472, in __getitem__
return self._getitem_tuple(key)
File "C:\Users\ckwij\Anaconda3\lib\site-packages\pandas\core\indexing.py", line 2013, in _getitem_tuple
self._has_valid_tuple(tup)
File "C:\Users\ckwij\Anaconda3\lib\site-packages\pandas\core\indexing.py", line 222, in _has_valid_tuple
self._validate_key(k, i)
File "C:\Users\ckwij\Anaconda3\lib\site-packages\pandas\core\indexing.py", line 1967, in _validate_key
if len(arr) and (arr.max() >= l or arr.min() < -l):
TypeError: len() of unsized object
So the way I have my data structured is that I have all my images in a folder with file paths set up as follows (the CSV files contain a small subset of image names and their corresponding class labels, since I wanted to initially start off testing and debugging with a small subset of the data before using the whole thing, which is 100s of thousands of images and slows everything to a crawl when trying to process):
Thanks for the information.
It should generally work. I guess something is still wrong with your pd.DataFrame.
Could you just create the Dataset and try to call dataset.labels_frame.iloc[0, 0].
If that’s throwing the same error, try to load the .csv offline, i.e. without the Dataset and debug it.
Alternatively, you could upload a small snippet of one .csv and I could take a look.
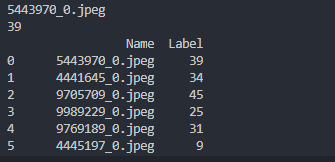
Tried calling dataset.labels_frame.iloc[0, 0] (where dataset was replaced with my training dataset), and it works fine (I also called dataset.labels_frame.iloc[0, 1] which is shown):
I used your sample .csv data and could create a Dataset and a WeightedRandomSampler.
Could you post your Dataset code completely? I’m not sure, how dataset.label_counts was calculated etc., so that I couldn’t debug your get_weighted_sampler method.
Definitely! Let me know if you need any other details. And thanks again for working with me on figuring this out.
Here’s the entire code for my custom Dataset class:
# Create custom Dataset class
class CameraCatalogueDataset(Dataset):
"""
Camera Catalogue dataset.
"""
def __init__(self, csv_file, data_folder, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
data_folder (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.labels_frame = pd.read_csv(csv_file)
self.data_folder = data_folder
self.transform = transform
self.labels = self.labels_frame.Label.unique()
self.label_counts = self.labels_frame.Label.value_counts()
self.num_classes = len(self.labels)
def __len__(self):
return len(self.labels_frame)
def __getitem__(self, idx):
image_name = data_folder / self.labels_frame.iloc[idx, 0]
image = Image.open(image_name)
image_label = self.labels_frame.iloc[idx, 1]
if self.transform:
image = self.transform(image)
return image, image_label
So at this point, let me just try posting all the code, since I’m still getting the same error with the fixes. Maybe I’m missing some small difference.
# Create custom Dataset class
class CameraCatalogueDataset(Dataset):
"""
Camera Catalogue dataset.
"""
def __init__(self, csv_file, data_folder, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
data_folder (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.labels_frame = pd.read_csv(csv_file)
self.data_folder = data_folder
self.transform = transform
self.labels = self.labels_frame.Label.unique()
self.label_counts = self.labels_frame.Label.value_counts()
self.num_classes = len(self.labels)
def __len__(self):
return len(self.labels_frame)
def __getitem__(self, idx):
image_name = data_folder / self.labels_frame.iloc[idx, 0]
image = torch.tensor([len(image_name)])
image_label = self.labels_frame.iloc[idx, 1]
if self.transform:
image = self.transform(image)
return image, image_label
# Function for getting weighted sampler for sampling Training set
def get_weighted_sampler(dataset):
sampler = None
# Create weight array for each training sample
sorted_label_counts = dataset.label_counts.sort_index()
label_weights = sum(sorted_label_counts.iloc[:]) / np.array(sorted_label_counts.iloc[:])
sampling_weights = []
for i in range(len(dataset)):
image_label = dataset.labels_frame.Label.iloc[i]
sampling_weights.append(label_weights[image_label])
sampler = torch.utils.data.sampler.WeightedRandomSampler(sampling_weights , len(sampling_weights))
return sampler
# Set up file paths
data_folder = Path('C:/Users/ckwij/Downloads/camera_catalogue/all_combined/')
training_data = data_folder / 'training_subset.csv'
#validation_data = data_folder / 'validation_subset.csv'
#test_data = data_folder / 'test_subset.csv'
# Set up transform for dataset
image_size = 224
dataset_transform = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Initialize dataset and its splits
camera_catalogue_training = CameraCatalogueDataset(csv_file=training_data, data_folder=data_folder, transform=dataset_transform)
#camera_catalogue_validation = CameraCatalogueDataset(csv_file=validation_data, data_folder=data_folder, transform=dataset_transform)
#camera_catalogue_test = CameraCatalogueDataset(csv_file=test_data, data_folder=data_folder, transform=dataset_transform)
# Create data samplers and loaders
training_sampler = get_weighted_sampler(camera_catalogue_training)
training_loader = DataLoader(camera_catalogue_training, batch_size=8, sampler=training_sampler)
#validation_loader = DataLoader(camera_catalogue_validation, batch_size=8, shuffle=True)
#test_loader = DataLoader(camera_catalogue_test, batch_size=8, shuffle=True)
for data, target in training_loader:
print(data, target)
I tried your code using some dummy images and it’s working.
As this issue is most likely unrelated to PyTorch, let’s move the discussion to private messages and post the final solution here.