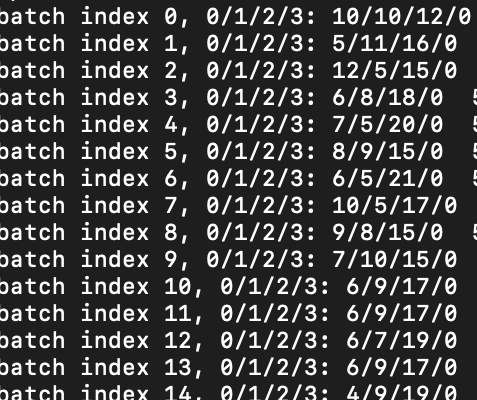
This is the distribution most of the times. Distribution is pretty random. If I remove the subset part and the labels part, then none of the class has samples as 0 in the batch, but the sampling contains majority from class 2,3 and minority from 1,4 which should not be the case.
Its sampling is random. When I run the code, sometimes it samples really badly, sometimes its better. Why is this so?
Yes train labels contains labels for complete set.
class Dataset(data.Dataset):
def __init__(self, list_IDs, labels, sample_weight, augment=True, shuffle=True):
#'Initialization'
self.list_IDs = list_IDs
self.labels=labels
self.augment = augment
self.shuffle = shuffle
self.sample_weight = sample_weight
# self.on_epoch_end()
#
def __getitem__(self, index):
np.random.seed(index)
# image_path = np.random.choice(a=self.list_IDs)
image_path = self.list_IDs[index]
my_path=image_path.replace("/home/ken.chang@ccds.io/mnt","/data" )
image = np.load(my_path)
if self.augment:
image = self.__preprocess_input(image)
label = (int(image_path[-5])-1)
image = TF.to_tensor(image).float()
label = torch.from_numpy(np.array(label))
return image, label
def __len__(self):
return int(len(self.list_IDs))
def on_epoch_end(self):
print("hello_epoch")
if self.shuffle == True:
c = list(zip(self.list_IDs,self.sample_weight, self.labels))
random.shuffle(c)
self.list_IDs, self.sample_weight, self.labels = zip(*c)
def __preprocess_input(self, image):
if np.random.rand(1)[0]>.5:
image = np.fliplr(image)
if np.random.rand(1)[0]>.5:
image = np.flipud(image)
image = rotate(image, angle=np.random.rand(1)[0]*45, mode='nearest', reshape=False)
return image
#draw from each sample with equal class probability
def cal_sample_weight(files):
print("file length ",len(files))
labels = [int(f[-5])-1 for f in files]
class_count = [labels.count(c) for c in np.unique(labels)]
print("class count is ",class_count)
weights_class = [((1.0/len(np.unique(labels)))/(cc)) for cc in class_count]
# weights_class = [1.0/(cc) for cc in class_count]
print("Weight class is ", weights_class)
weight_array = np.array([weights_class[l] for l in labels])
return torch.from_numpy(weight_array)
# return weight_array
os.chdir('/data/2015P002510/MammoDensity/scripts_preprocessing/splits')
with open("Train_images_DMIST2.txt", "rb") as fp:
Train_files1 = pickle.load(fp)
with open("Train_images_DMIST3.txt", "rb") as fp:
Train_files2 = pickle.load(fp)
with open("Train_images_DMIST4.txt", "rb") as fp:
Train_files3 = pickle.load(fp)
with open("Train_images_MGH.txt", "rb") as fp:
Train_files4 = pickle.load(fp)
Train_files = Train_files1+Train_files2+Train_files3+Train_files4
#
with open("Val_images_DMIST2.txt", "rb") as fp:
Val_files1 = pickle.load(fp)
with open("Val_images_DMIST3.txt", "rb") as fp:
Val_files2 = pickle.load(fp)
with open("Val_images_DMIST4.txt", "rb") as fp:
Val_files3 = pickle.load(fp)
with open("Val_images_MGH.txt", "rb") as fp:
Val_files4 = pickle.load(fp)
Val_files = Val_files1+Val_files2+Val_files3+Val_files4
print([(int(image_path[-5])-1) for image_path in Train_files[0:32]])
random.shuffle(Train_files)
random.shuffle(Val_files)
print([(int(image_path[-5])-1) for image_path in Train_files[0:32]])
Train_labels = [(int(image_path[-5])-1) for image_path in Train_files]
Val_labels = [(int(image_path[-5])-1) for image_path in Val_files]
#
Train_sample_weight = cal_sample_weight(Train_files)
print(Train_sample_weight[0:32])
Val_sample_weight = cal_sample_weight(Val_files)
# LOADING DATASET
training_set = Dataset(list_IDs=Train_files,labels=Train_labels, sample_weight=Train_sample_weight, shuffle=True, augment=True)
print("length of train is ", len(training_set))
sampler_train = torch.utils.data.sampler.WeightedRandomSampler(weights = Train_sample_weight, num_samples=len(training_set))
trainloader = DataLoader(torch.utils.data.Subset(training_set,Train_labels), batch_size=batch_size, sampler=sampler_train,num_workers=24, pin_memory=True)
# trainloader = DataLoader(dataset=training_set, batch_size=batch_size, sampler=sampler_train,shuffle=False, num_workers=24, pin_memory=True)
test_set = Dataset(Val_files,labels=Val_labels, sample_weight=Val_sample_weight, augment=False)
print("lenght of val is ", len(test_set))
sampler_test = torch.utils.data.sampler.WeightedRandomSampler(weights = Val_sample_weight, num_samples=len(test_set))
testloader = DataLoader(dataset=test_set, batch_size=batch_size, sampler=sampler_test, num_workers=24, pin_memory=True)
