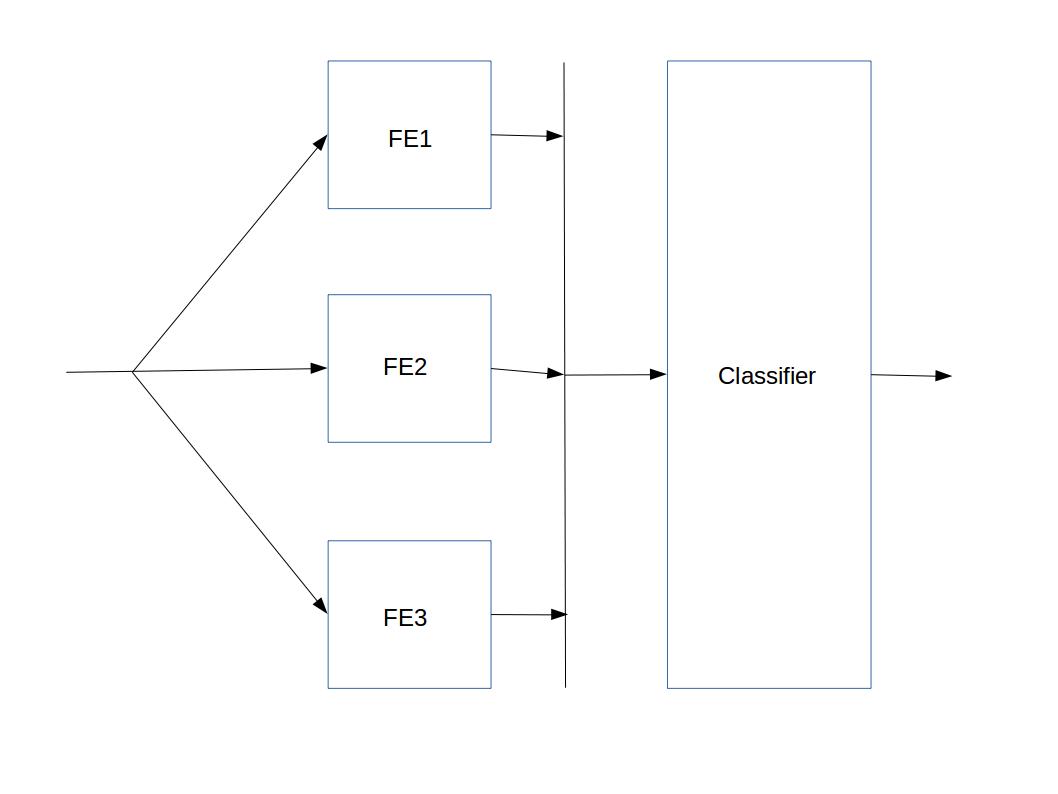
I am trying to create a network which contains separate feature extraction sub-networks (FE) for different types of features. FEs give features which are concatenated to give final feature which is then fed to a classifier.
The learning scenario is like this:
Each FE learns using samples from a specific class. So loss for a given FE should be restricted to that particular FE only and not allowing parameters of other FE to be learned. But as classifier takes concatenated feature classifier loss should be back propagated to all FEs.
So learning is a kind of iterative I. 1). learn FE one after another 2).and then using features of all FE learn classifier.
However, when I learn say FE1, loss for FE1 is restricted to FE1. But when I learn FE2, weights of FE1 and FE2 are getting updated but weights of FE3 are not updated (Ideally I would want only weights of FE2 to get updated.). Similarly, when FE3 is learned weights of all FE1, FE2, FE3 are updated. I have made classifier loss zero to avoid updating of weights of FEs due to classifier loss. So, when I learn the later FE, weights of all the previous FEs are also updated. I am storing the FE module in a list.
Further, lets say I am learning FE2. I observed that gradients of FE1 weights are zeros (I checked norm of gradients also) but still FE1 weights are updating.
I am not able to understand why this leakage of loss is happening across different sub-networks and why the weights are updated even if gradients are zero.
Any help would be greatly appreciated.
Thanks.