I try to implement the disconnection of weights, i.e., the specific connection is always 0. It sounds like masked_scatter_, but I found it could not be autograded.
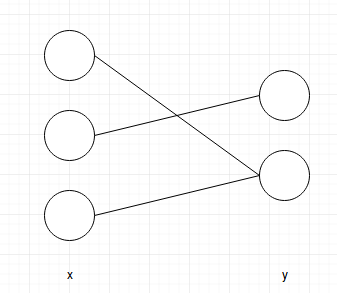
While I am not clear about the picture you have posted - (why is the shape of x (3,2) if there are just three input nodes). One clear issue with your code though is that none of the variables have a requires_grad=True. For autograd to track stuff at least one of the inputs should have requires_grad=True.
As far as the implementation of the diagram is concerned I would do something like this (assuming each node yields a scalar in the first layer):
Can you clarify what do you mean by “keep tasked”?
weights.grad_fn is none because the gradients would be computed wrt weights. At the end when you finally get a scalar and call .backward the right gradients will be calculated in weights.grad. You can use an optimizer or manually update the weights from there.
Yes, sure, just one more little question. For the “keep tasked”, I actually refer to “disconnected”. So if I use auto back-propogation, will the disconnection still be disconnected please?
 .
.