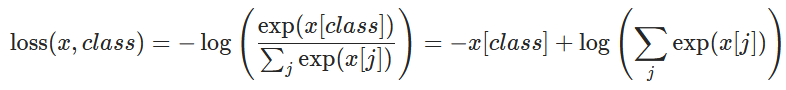Cross-entropy with weights is defined as follows [1]:
loss(x,class) = weight[class](−x[class] + log(∑_j exp(x[j])))
Why the normalization term (denominator of softmax regression) is weighted by weight[class], too? Shouldn’t it be the sum of weighted exponentials as below?
In my understanding, weight is used to reweigh the losses from different classes (to avoid class-imbalance scenarios), rather than influencing the softmax logits.
Consider that the loss function is independent of softmax.
That is, In the cross-entropy loss function, L_i(y, t) = -t_ij log y_ij (here t_ij=1)
y_i is the probability vector that can be obtained by any other way than just softmax. With weight, we are trying to reweigh L_i(y, t) based on the ground truth class.
Technically, Cross-entropy (CE) is independent of softmax and a generic concept to measure distances/differences between two probability distributions. It so happens that one of the ways to get probability distributions in deep learning (especially for classification problems) is to use softmax. Ideally, CE loss can be realized by log_softmax + NLL loss. However, for numerical stability reasons, CE loss in pytorch is coupled with Softmax directly.
I understand that, but in this case aren’t they the same? log_softmax + NLL loss should be the same thing as the negative log-likelihood of multinomial logistic regression (which I called softmax regression before). The equation in my previous post shows that the loss is defined as the negative log-likelihood of multinomial logistic regression (I suppose x[class] is class_weights*input).
If I were to define a prior distribution over class labels, I would write something like exp(w_k * x)*q_k / \sum_j (exp(w_j * x)*q_j) where x is the input, w_k is the parameter vector of class k, and q_k is the weight of class k. I think, this way I would get the correctly normalized probabilities considering the weights as well. And I would end up something different than the weighted loss given in [1]. Btw my first attempt (second equation in my first post) seems to be wrong.
I am a bit lost about this prior distribution concept.
However, I have some counterpoints with your formulation:
when you multiply q_k in the numerator and take log (for CE loss), q_k will be simply ignored as log q_k is a constant.
By trying to multiply q_x with exp() terms (i.e., exp(w_j * x)*q_j), it seems like you are trying to add a constant bias (i.e., exp(w_j * x)*q_j = exp(w_j * x)*exp(log q_j) = exp(w_j * x + log q_j). The network might learn to pump up the logits to avoid this bias (I am not sure!).