Hi All,
I’m trying Deep learning network in pytorch for image classification and my dataset is class imbalanced. Hence I’ve applied the class weights while calculating the cross entropy loss during training.
However, am having following doubt,
Do we apply the class weights to the loss function for validation/dev set?
If so, would it not mislead us from the actual target?
Or
We have to apply the weights to loss function only during training and not during validation?
Pls clarify
1 Like
I would assume the weights are only used during training to add a penalty for misclassified minority classes. I’m not sure if e.g. early stopping should also be used with a weighted validation loss, so maybe @rasbt could give a hint on this topic, as he’s really experienced in this domain.
1 Like
I recommend using a balanced dataset for evaluation because on an imbalanced dataset, e.g., accuracy is misleading. The loss function would only be applied during training then (I assume you want to measure sth like “accuracy” on the validation/test set).
Furthermore, to get more insights into the classification performance with and without loss weighting during training, i recommend looking at the confusion matrices on the validation/test sets when you train with and without weighting.
It depends on what you actual target is – that’s something you need to decide depending on the goal for which you train the model.
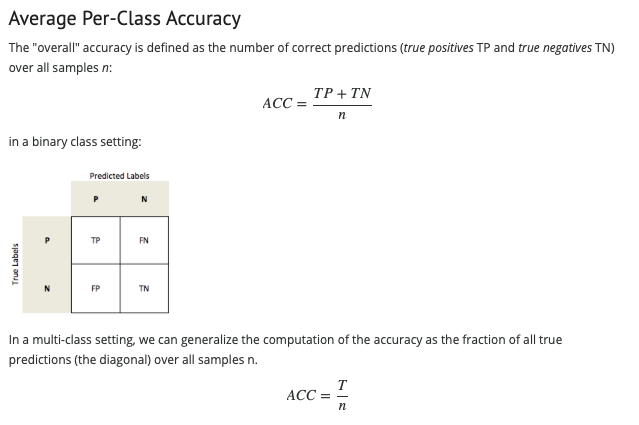
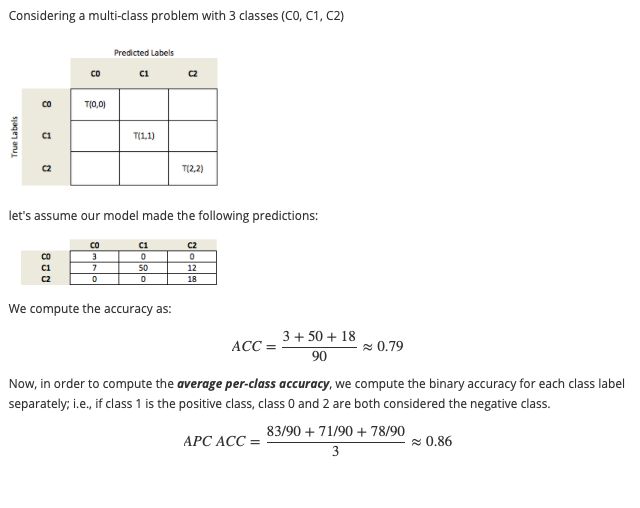
Lastly, a metric that might be helpful here would be the “average-per-class accuracy” – I’ve summarized it here: scoring: computing various performance metrics - mlxtend
I’m not sure if e.g. early stopping should also be used with a weighted validation loss, so maybe
I’d say the concept of early stopping is not necessarily related to the class imbalanced problem. It can be used if you notice an increasing degree of overfitting (measured on the validation set) when you continue training, but this can happen with/without class imbalance. I don’t think there’s a direct relationship between these two issues.
4 Likes
Thanks for the detailed info on validation part. The classification of model performance improved after applying the class weights during training.
My Train and Validation set comes from the exact same imbalanced class distribution. I am using weighted CrossEntropy loss function to calculate training loss. As it would be unfair to use weighted loss function for Validation, I interpret from above discussion, not to calculate validation loss and rely on Validation accuracy only. What criterion should I use for early stopping in this case? Or the plain CrossEntropy loss without weights can be reasonable for validation. Please let me know your suggestion. Thank you.