Hi,
I am new to PyTorch and have been working on the CIFAR10 dataset. When I try to plot the accuracy history over the training epochs, I see a weird behavior. The accuracy up to the penultimate epochs are all negligible, after which it shoots up to something that is reasonable. I get something like the following
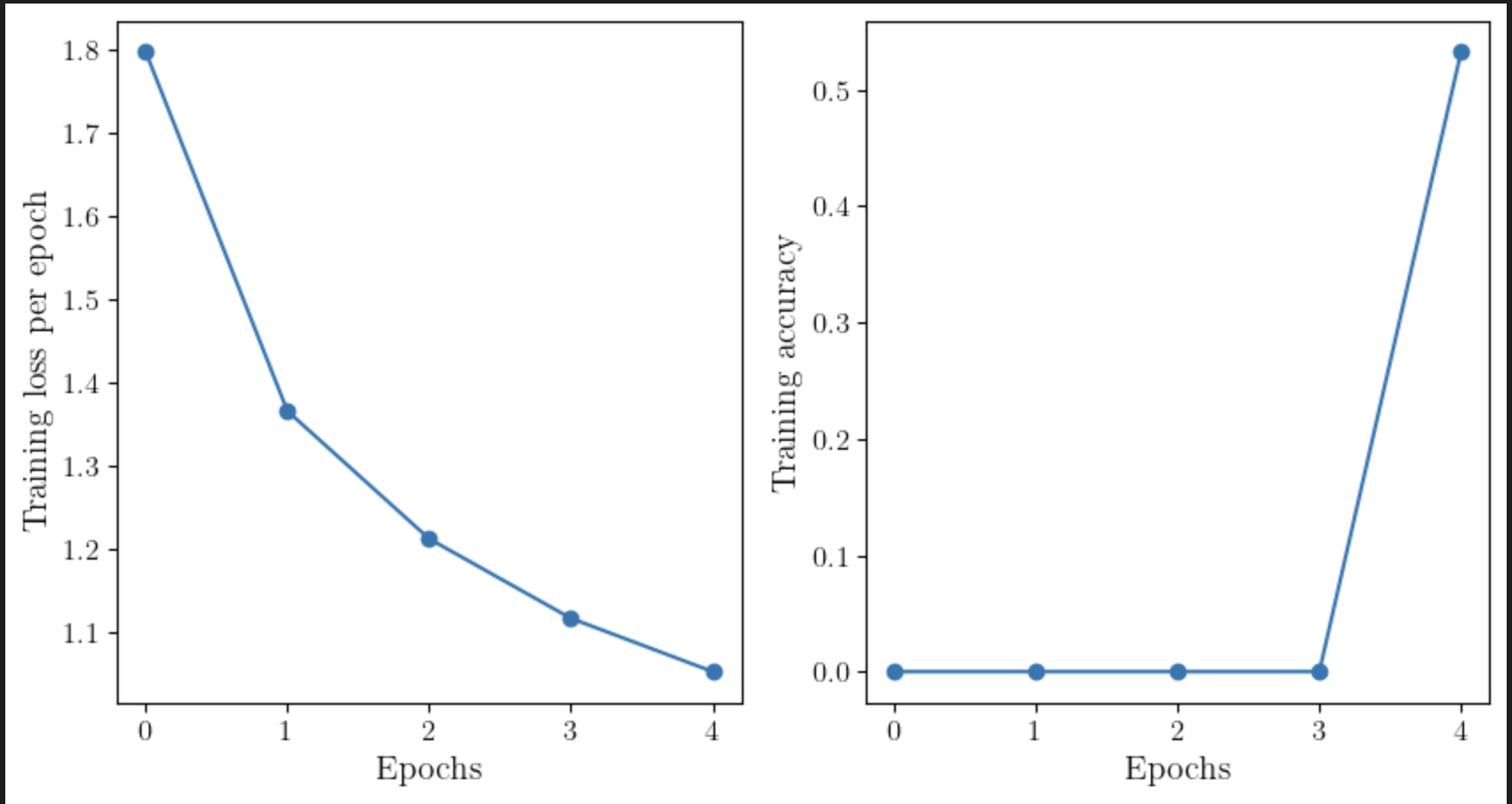
The training loop that I have is
def train(dataloader, model, loss_fn, optimizer, num_epochs):
size = len(dataloader.dataset)
batch_size = len(dataloader)
loss_train = np.zeros(num_epochs) # Loss history per epoch during training
acc_train = np.zeros(num_epochs) # Accuracy history per epoch during training
running_correct = 0 # Keeps track of the number of correct classifications
running_total = 0
model.train()
for epoch in range(num_epochs):
for i, (image, label) in enumerate(dataloader):
image, label = image.to(device), label.to(device)
'''
Calculate prediction and loss function per epoch
'''
label_pred = model(image)
loss = loss_fn(label_pred, label)
'''
Backpropagating the loss function to re-adjust weights
'''
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss_train[epoch] += loss.item()*image.size(0) # Accumulated loss per training batch
_, predicted = torch.max(label_pred, 1)
running_total += label.size(0)
running_correct += (predicted == label).sum().item()
acc_train[epoch] = running_correct # Number of correct predictions per training batch
if (i + 1) % 2500 == 0:
print (f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{batch_size}], Loss: {loss:.4f}')
loss_train[epoch] = loss_train[epoch]/size
acc_train = acc_train/running_total # Proportion of accurate predictions
return loss_train, acc_train
I am not sure why I am seeing this behavior.
Regards