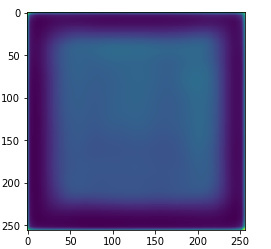
I tried to implement a FCN with PyTorch ,which I have previously implemented in Torch. The BCE losses drops to around 0.05 after several epoches, but when I simply run a inference, even an image in the training dataset, the result is just something mess:
really can not understand why. Any help?
The main training loop:(I use my own image dataloader and training loop, label is either 1 or 0)
optimizer = optim.Adam(fcn.parameters(), lr=opt.lr)
def train(epoch):
np.random.shuffle(name_list)
epoch_lossSeg = 0.0
for iteration in range(0, dataset_size,opt.batchSize):
batch_img_tensor = torch.FloatTensor(opt.batchSize, 3, opt.h, opt.w)
batch_annotation_tensor = torch.FloatTensor(opt.batchSize,1,opt.h, opt.w)
# get a batch input and label
for i in range(iteration+0, iteration + opt.batchSize):
img_ = Image.open(opt.train_img_path + '/' + name_list[i])
img = img_.resize(img_size,Image.BILINEAR)
batch_img_tensor[ i-iteration ] = torch.from_numpy(np.array(img)).float()
annotation_ = Image.open(opt.train_label_path + '/' + name_list[i])
annotation = annotation_.resize(img_size,Image.NEAREST)
batch_annotation_tensor[i-iteration] = torch.from_numpy(np.array(annotation)).float()
# PyTorch use pixel values from 0 to 1
batch_img_tensor = batch_img_tensor
batch_annotation_tensor = batch_annotation_tensor / 255
batch_input = Variable(batch_img_tensor).cuda()
batch_annotation = Variable(batch_annotation_tensor).cuda()
optimizer.zero_grad()
output = fcn.forward(batch_input)
err_seg = criterion(output,batch_annotation)
err_seg.backward()
optimizer.step()
inference code:
img = Image.open('...')
size = 256,256
img = img.resize((256,256))
input_tensor = torch.FloatTensor(1,3,256,256)
input_tensor[0] = torch.from_numpy(np.asarray(img))
input_tensor = input_tensor.float()
input_var = Variable(input_tensor)
fcn.eval()
out = fcn.forward(input_var.cuda())
from matplotlib import pyplot as plt
import numpy
out = out.cpu()
out_img = out.data[0]
plt.imshow(out_img.numpy()[0])
do you perform the same image pre-processing during training and testing?
To double check, during training you could save some example images of the training predictions (making sure that you are saving after softmax if using NLLLoss, keeping only the prediction channel, etc). This could show if you are wrongly pre-processing your test images.
Maybe. I didn’t check in details your code, but are you using a pre-trained network?
And if yes, make sure that the image pre-processing is the same (you are not subtracting the imagenet mean/std, so if you use models from modelzoo, it won’t work).
Also, it would make your life easier (and the code would be faster as well) if you implemented a Dataset, and used a dataLoader from pytorch (as it would load the images using multiple threads).
I need to annotation tensors to be batchSize*1*256*256 with 0 and 1 pixel values. But when I tried to load them using Dataset class, the tensors just become the rgb channel images. Where should I change ?
Besides, is there any difference between the following two ways to save models? I used the second one
To load the images without converting them to RGB, just don’t pass the .convert('RGB') option to PIL.
The difference between both is that in the first one, you just save the parameters, while the second you save the full structure. The first one is advised, because it’s clear what the model structure is (you need to have a file that defines it), but both should work just fine.