import argparse
import datetime
import json
import os
from pathlib import Path
import sys
import time
# import warnings
ROOT = "/".join(os.path.dirname(os.path.abspath(__file__)).split("/")[:-2])
sys.path.append(ROOT)
# isort: split
import numpy as np
import torch
torch.autograd.set_detect_anomaly(True)
import torch.backends.cudnn as cudnn
from torch.distributed.elastic.multiprocessing.errors import record
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision.transforms import functional
# isort: split
# warnings.filterwarnings("ignore", category=DeprecationWarning)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# --------------------- utils ---------------------
def to_dist(model, local_rank):
model = nn.SyncBatchNorm.convert_sync_batchnorm(model)
model = nn.parallel.DistributedDataParallel(
model, device_ids=[local_rank]
)
return model
def message_bce_loss(outputs, targets, margin=1.0):
"""
Compute the message BCE loss.
Args:
margin: temperature of the sigmoid of the BCE loss
"""
if torch.min(targets) == -1:
targets = 0.5 * (targets + 1)
return F.binary_cross_entropy_with_logits(
outputs / margin, targets, reduction="mean"
)
def generate_messages(n, k):
"""
Generate random original messages.
Args:
n: Number of messages to generate
k: length of the message
Returns:
msgs: boolean tensor of size nxk
"""
return torch.rand((n, k)) > 0.5
# -------------------------------------------------
# --------------------- models ---------------------
class ConvBNRelu(nn.Module):
"""
Building block used in HiDDeN network. Is a sequence of Convolution, Batch Normalization, and ReLU activation
"""
def __init__(self, channels_in, channels_out, stride=1):
super(ConvBNRelu, self).__init__()
self.layers = nn.Sequential(
nn.Conv2d(channels_in, channels_out, 3, stride, padding=1),
nn.BatchNorm2d(channels_out),
nn.ReLU(),
)
def forward(self, x):
return self.layers(x)
def l2_normalization(x):
l2_norm = torch.linalg.vector_norm(x, dim=(1, 2, 3)).view(-1, 1, 1, 1) # l2 norm of each image
num_pixels = math.prod(x.size()[1:])
return x / l2_norm * math.sqrt(num_pixels)
def delta_process(delta, last_process):
if last_process == "tanh":
return F.tanh(delta)
elif last_process == "l2":
return l2_normalization(delta)
elif last_process == "tanh-l2":
return l2_normalization(F.tanh(delta))
elif last_process == "linf":
denom = torch.amax(torch.abs(delta), dim=(1, 2, 3), keepdim=True)[0] # max of each image
return delta / denom
elif last_process == "none":
return delta
else:
raise NotImplementedError
class VanillaEncoder(nn.Module):
"""
Inserts a watermark into an image.
"""
def __init__(self, num_blocks, num_bits, channels, normalizer=None, last_process="tanh", output="w"):
super(VanillaEncoder, self).__init__()
layers = [ConvBNRelu(3, channels)]
for _ in range(num_blocks - 1):
layer = ConvBNRelu(channels, channels)
layers.append(layer)
self.conv_bns = nn.Sequential(*layers)
self.after_concat_layer = ConvBNRelu(channels + 3 + num_bits, channels)
self.final_layer = nn.Conv2d(channels, 3, kernel_size=1)
assert last_process in ["tanh", "none", "l2", "linf", "tanh-l2"]
self.last_process = last_process
self.normalizer = normalizer
assert output in ["w", "imgw"]
self.output = output
def forward(self, imgs, msgs):
# take normalizer as part of the model
# so that we can easily handle image pixel
# value range in the training/testing script
if self.normalizer is not None:
imgs = self.normalizer(imgs)
msgs = msgs.unsqueeze(-1).unsqueeze(-1) # b l 1 1
msgs = msgs.expand(-1, -1, imgs.size(-2), imgs.size(-1)) # b l h w
encoded_image = self.conv_bns(imgs)
concat = torch.cat([msgs, encoded_image, imgs], dim=1)
residual = self.after_concat_layer(concat)
residual = self.final_layer(residual) # b 3 h w
if self.output == "w":
return delta_process(residual, self.last_process)
elif self.output == "imgw":
return 0.5 * (delta_process(residual, self.last_process) + 1) # [-1, 1] -> [0, 1]
class VanillaDecoder(nn.Module):
"""
Decoder module. Receives a watermarked image and extracts the watermark.
"""
def __init__(self, num_blocks, num_bits, channels, normalizer=None, redundancy=1):
super(VanillaDecoder, self).__init__()
layers = [ConvBNRelu(3, channels)]
for _ in range(num_blocks - 1):
layers.append(ConvBNRelu(channels, channels))
layers.append(ConvBNRelu(channels, num_bits * redundancy))
layers.append(nn.AdaptiveAvgPool2d(output_size=(1, 1)))
self.layers = nn.Sequential(*layers)
self.linear = nn.Linear(num_bits * redundancy, num_bits * redundancy)
self.num_bits = num_bits
self.redundancy = redundancy
self.normalizer = normalizer
def forward(self, img_w):
# take normalizer as part of the model
# so that we can easily handle image pixel
# value range in the training/testing script
if self.normalizer is not None:
img_w = self.normalizer(img_w)
x = self.layers(img_w) # b d 1 1
x = x.squeeze(-1).squeeze(-1) # b d
x = self.linear(x)
x = x.view(-1, self.num_bits, self.redundancy) # b k*r -> b k r
x = torch.sum(x, dim=-1) # b k r -> b k
return x
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
# https://github.com/BorealisAI/advertorch/blob/master/advertorch/utils.py
class Normalizer(nn.Module):
def __init__(self, mean=IMAGENET_MEAN, std=IMAGENET_STD):
super(Normalizer, self).__init__()
if not isinstance(mean, torch.Tensor):
mean = torch.tensor(mean).view(1, 3, 1, 1)
if not isinstance(std, torch.Tensor):
std = torch.tensor(std).view(1, 3, 1, 1)
self.register_buffer("mean", mean)
self.register_buffer("std", std)
def forward(self, tensor):
return tensor.sub(self.mean).div(self.std)
def extra_repr(self):
return "mean={}, std={}".format(self.mean, self.std)
# --------------------------------------------------
def main(dist=True):
# Distributed mode
if dist:
local_rank = int(os.environ["LOCAL_RANK"])
torch.distributed.init_process_group(
init_method="env://",
backend="nccl",
)
torch.cuda.set_device(local_rank)
cudnn.benchmark = False
cudnn.deterministic = True
else:
local_rank = 0
# Set seeds for reproductibility
seed = local_rank
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
# Build encoder
normalizer = Normalizer()
encoder = VanillaEncoder(
num_blocks=4,
num_bits=32,
channels=64,
last_process="none",
normalizer=normalizer,
output="imgw",
)
# Build decoder
print(">>> Building decoder...")
decoder = VanillaDecoder(
num_blocks=8,
num_bits=32,
channels=64,
normalizer=normalizer,
)
# Adapt bn momentum
all_modules = [*decoder.modules(), *encoder.modules()]
for module in all_modules:
if type(module) == torch.nn.BatchNorm2d:
module.momentum = 0.01
# Distributed training
encoder.to(device)
decoder.to(device)
if dist:
encoder = to_dist(encoder, local_rank)
decoder = to_dist(decoder, local_rank)
# Build optimizer and scheduler
to_optim = [*encoder.parameters(), *decoder.parameters()]
optimizer = torch.optim.AdamW(to_optim, lr=0.001)
# just a forward pass
encoder.train()
decoder.train()
imgs = 0.5 * torch.ones(32, 3, 128, 128).to(device, non_blocking=True) # b c h w
msgs_ori = generate_messages(imgs.shape[0], 32).to(
device, non_blocking=True
) # n k
msgs = 2 * msgs_ori.type(torch.float) - 1 # b k
imgs_w = encoder(imgs, msgs).clamp(0, 1) # b c h w
outputs = []
for ii, img_w in enumerate(imgs_w):
outputs.append(decoder(img_w.unsqueeze(0)))
outputs = torch.cat(outputs, dim=0)
loss = message_bce_loss(outputs, msgs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--dist", action="store_true")
args = parser.parse_args()
main(args.dist)
Hi @ptrblck ! Please see above the code snippet; it’s still a bit long because of those model architecture definitions.
The command to reproduce the error is:
CUDA_VISIBLE_DEVICES="2,3" \
torchrun --nproc_per_node=2 --nnodes 1 --master_port 16000 pretrain_minimal.py --dist
which uses DDP, and the following error and traceback will be got:
/home/jz288/anaconda3/envs/sd2wm/lib/python3.8/site-packages/torch/autograd/init.py:200: UserWarning: Error detected in DivBackward0. Traceback of forward call that caused the error:
File “pretrain_minimal.py”, line 295, in
main(args.dist)
File “pretrain_minimal.py”, line 281, in main
outputs.append(decoder(img_w.unsqueeze(0)))
File “/home/jz288/anaconda3/envs/sd2wm/lib/python3.8/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/home/jz288/anaconda3/envs/sd2wm/lib/python3.8/site-packages/torch/nn/parallel/distributed.py”, line 1156, in forward
output = self._run_ddp_forward(*inputs, **kwargs)
File “/home/jz288/anaconda3/envs/sd2wm/lib/python3.8/site-packages/torch/nn/parallel/distributed.py”, line 1110, in _run_ddp_forward
return module_to_run(*inputs[0], **kwargs[0]) # type: ignore[index]
File “/home/jz288/anaconda3/envs/sd2wm/lib/python3.8/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “pretrain_minimal.py”, line 173, in forward
img_w = self.normalizer(img_w)
File “/home/jz288/anaconda3/envs/sd2wm/lib/python3.8/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “pretrain_minimal.py”, line 199, in forward
return tensor.sub(self.mean).div(self.std)
(Triggered internally at …/torch/csrc/autograd/python_anomaly_mode.cpp:114.)
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
Traceback (most recent call last):
File “pretrain_minimal.py”, line 295, in
main(args.dist)
File “pretrain_minimal.py”, line 286, in main
loss.backward()
File “/home/jz288/anaconda3/envs/sd2wm/lib/python3.8/site-packages/torch/_tensor.py”, line 487, in backward
torch.autograd.backward(
File “/home/jz288/anaconda3/envs/sd2wm/lib/python3.8/site-packages/torch/autograd/init.py”, line 200, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [1, 3, 1, 1]] is at version 35; expected version 34 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
This time fortunately it showed that the error was with the input normalization tensor.sub(self.mean).div(self.std). However, I’m still confused as this is not really an inplace operation to my understanding.
Also, the following command without using DDP runs fine (no error):
CUDA_VISIBLE_DEVICES="2" python pretrain_minimal.py
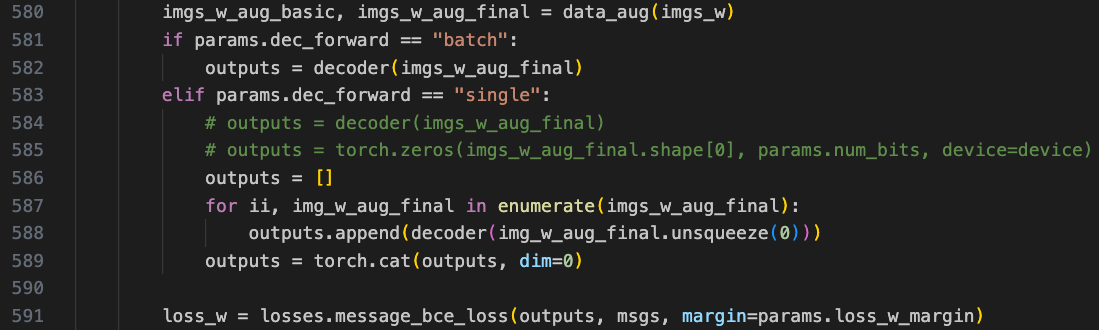
And lastly, making the following changes at the end of main() (passing the whole batch rather than each single sample through the decoder) will also avoid the error:
#outputs = []
#for ii, img_w in enumerate(imgs_w):
# outputs.append(decoder(img_w.unsqueeze(0)))
#outputs = torch.cat(outputs, dim=0)
outputs = decoder(imgs_w)
To summarize, the inplace-operation-breaking-gradient error only occurs when 1) DDP is used plus 2) each single input is passed through the model. Thank you for taking time to look into this! @ptrblck