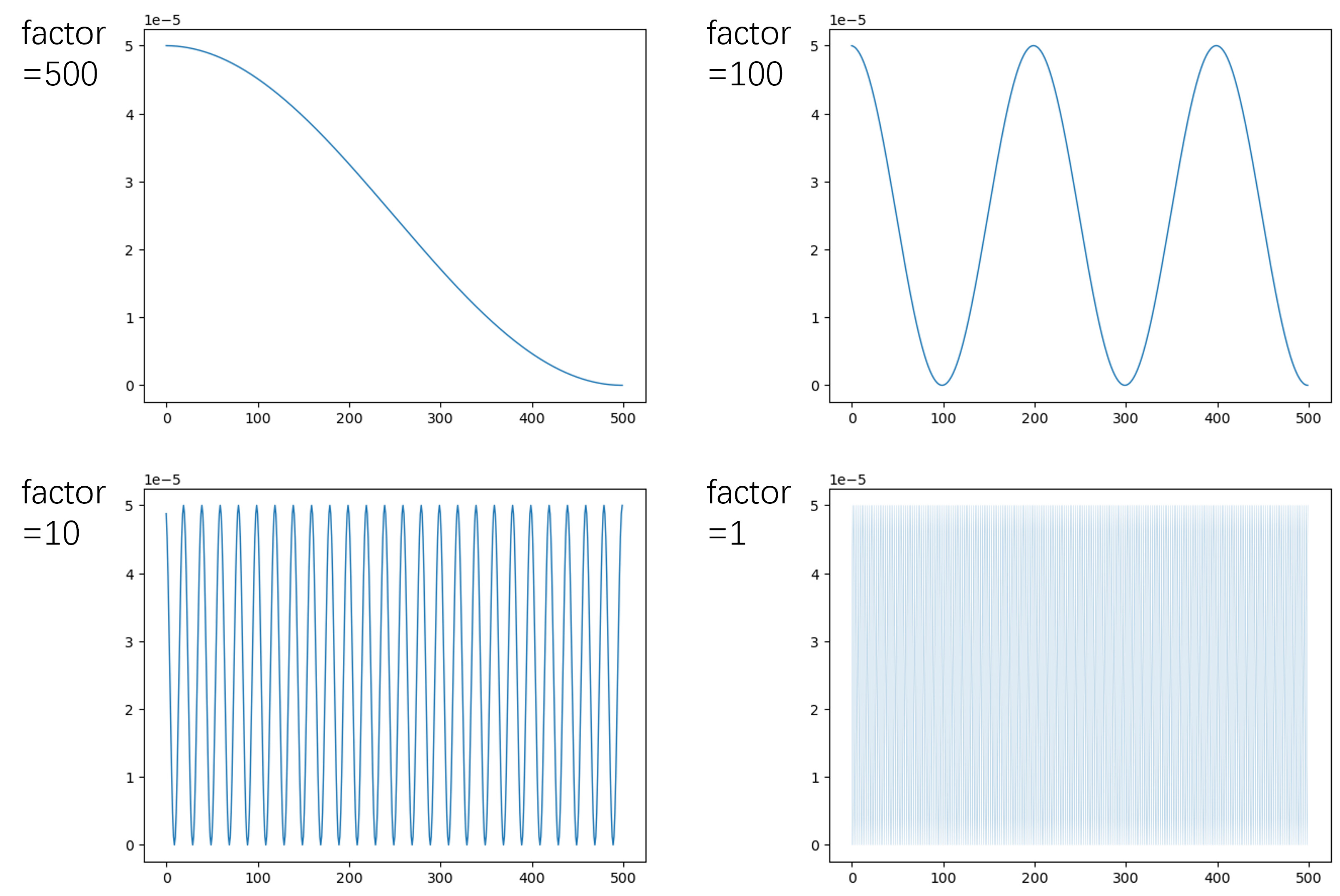
Hi guys, I recently systematically compared training Point Cloud Transformer (Guo2020) for 500 epochs with Adam optimizer and with CosineAnnealingLR at varied Tmax. The selection of Tmax is [1,10,100,500]*num_batches. Before training, I checked the expected apparent learning rate patterns (as the value of optimizer.param_groups[0][‘lr’]), they look as follows.
The code snippet to reproduce the result is:
import torch
import torch.nn as nn
num_batches = n
num_epochs = 500
learning_rate = 5e-5
tensor_sample = torch.tensor([1.0],requires_grad=True)
optimizer = torch.optim.Adam([tensor_sample],lr=learning_rate,betas=(0.9,0.99))
factor = 1 #10,100,500
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, num_batches*factor, eta_min=0, last_epoch = -1)
for epoch in range(num_epochs):
for batch in range(num_batches):
scheduler.step()
record(epoch, optimizer.param_groups[0]['lr'])
In the actual training process, the optimizer and schduler are set in the very same way, and also optimizer.param_groups[0][‘lr’] was recorded. However, in the results it showed that when factor is as low as 1, the apparent learning rate displayed an interesting but unexpected pattern, while higher factors displayed very the same patterns as before. Shown below.
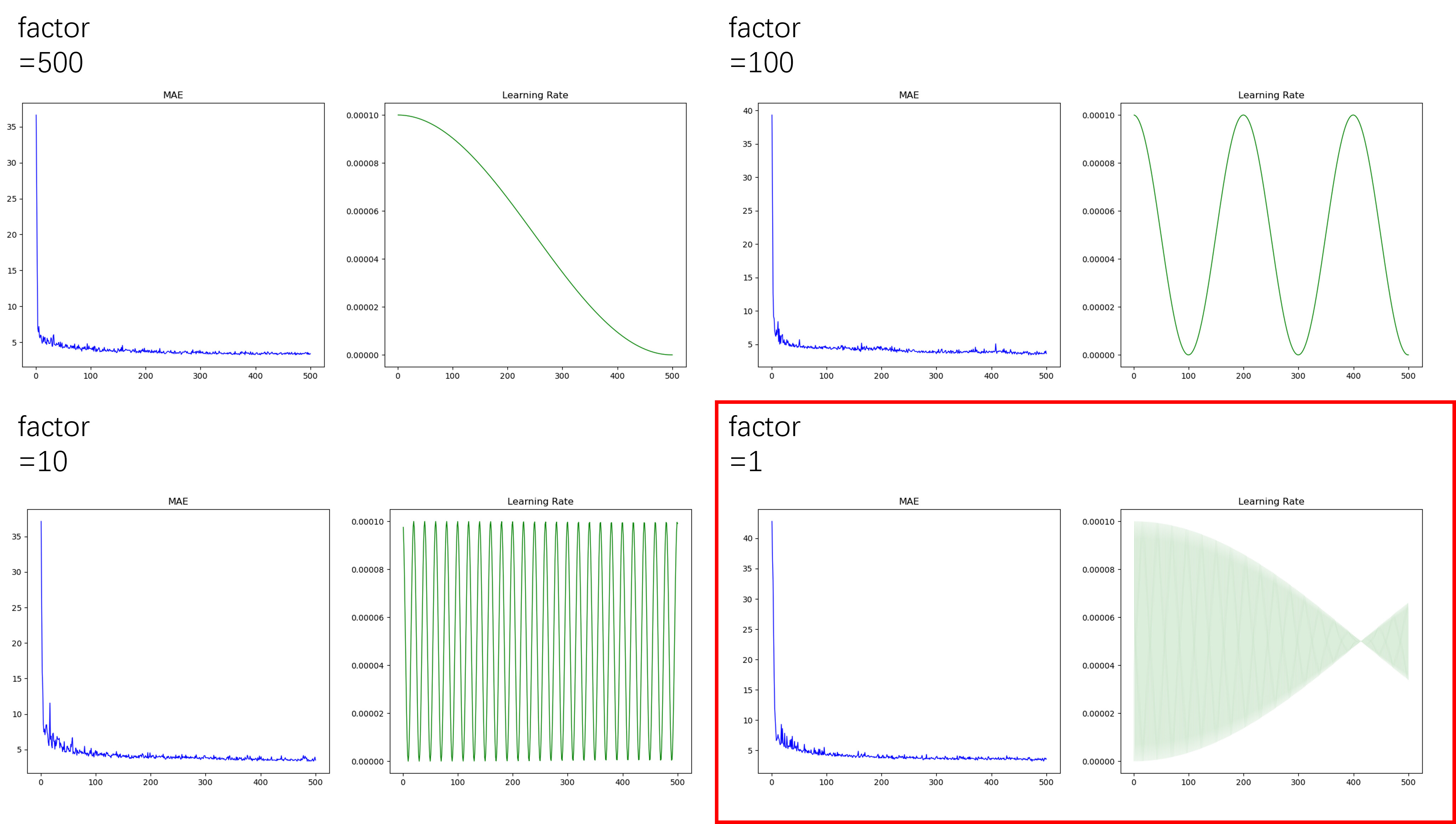
Any idea on the cause? Thanks.