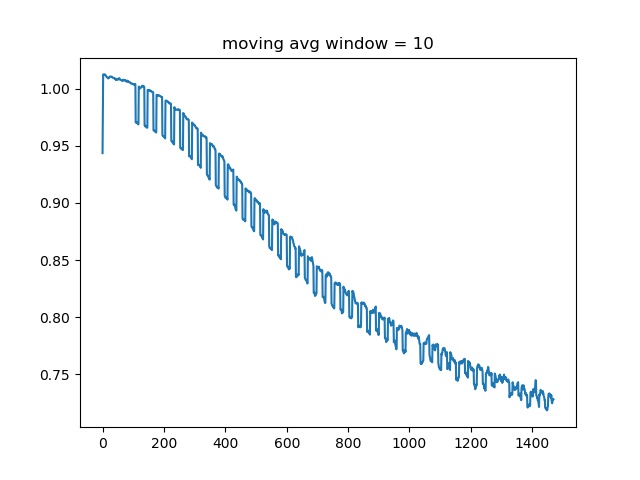
I have an application that outputs a weird loss curve :
I don’t understand why there are recurrent patterns in the loss curve. In my program, the total loss consists of three L1 losses. And this curve visualize one of the L1 loss.
Is it because some problems in my code? This is how I calculate the total loss:
Here, the dataloader outputs data, x, y. Here x and y are both transforms for data.
The network is an autoencoder for data only, which will output recon_dat. The, func is a function that will generate the reconstructed x and y for the recon_dat.
The total loss is the sum of L1 loss between 1) dat and recon_dat, 2) x and recon_x, 3) y and recon_y.
Not sure what you loss function is, but maybe you are not taking the average over the minibatch size – I guess your dataset is not evenly divisible by the minibatch size and then you end up with 1 minibatch that is much smaller than others in each epoch.
@rasbt Thanks for the answer! I checked the dataloader and this is not due to different minibatch size, though you have kindly raised a point I have not considered.
For this problem BCELossWithLogits is a better choice than L1 loss.
Have you shuffled the data properly? Another reason would be, that in one-minibatch the dominating background say is of color (12, 12, 12) and in other minibatch background is of color(200, 200, 200). Expanding on this idea, your data in different dataloader steps is most probably biased towards some class.
Thanks for the reply! I did used a “shuffle=True” in my dataloader. I also checked the max absolute values for data points and the data is normalized to N(0, 1).
On another note, your idea makes me think could this because of I have a small dataset? There are only 947 samples and my minibatch size is 25. Maybe one dominant datapoint just somehow changes the loss too much.
I’ll continue playing with my network and update here if I found anything. Thanks!