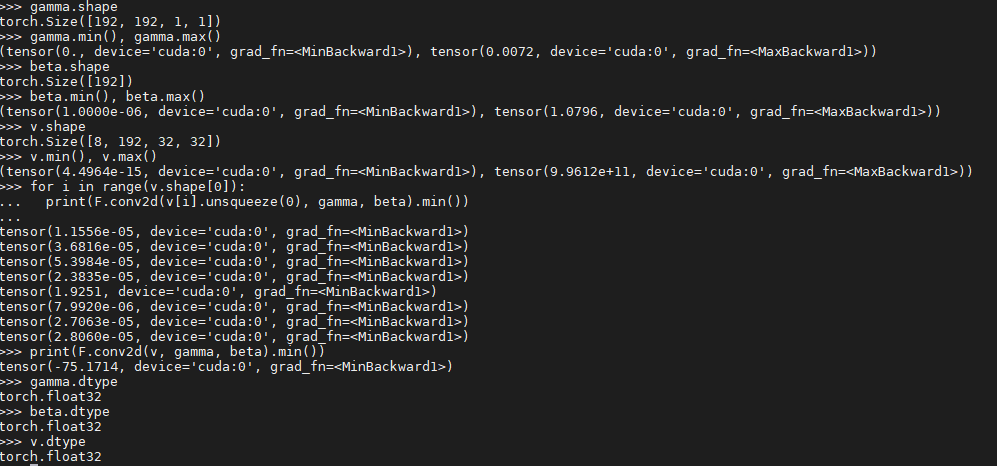
Please refer to the attached image.
I had three non-negative tensors of float32 type, gamma: kernel for conv2d, beta: bias for conv2d, and v: an input.
When convolving seperately for each instance of minibatch v, I got normal outputs of non-negative values.
However, convolution over the entire v produced the weird outputs with a negative minimum.
Why did this happen?
Please help me!
Thanks.
========================================================
Reproducing:
Link for the data: weird_conv2d.pt
import torch
import torch.nn.functional as F
# loading
params = torch.load('./weird_conv2d.pt')
v = params['v']
gamma = params['gamma']
beta = params['beta']
# check the minimums
print('v', v.min().item())
print('gamma', gamma.min().item())
print('beta', beta .min().item())
''' outputs:
v 1.7985612998927536e-14 919835639808.0
gamma 0.0 0.007155213970690966
beta 9.999999974752427e-07 1.0796115398406982
'''
# strange outputs
print(F.conv2d(v, gamma, beta).min().item())
''' outputs:
-51.17139434814453
'''
for i in range(v.shape[0]):
print(F.conv2d(v[i].unsqueeze(0), gamma, beta).min().item())
''' outputs:
1.6701818822184578e-05
1.5259909559972584e-05
3.263943290221505e-05
3.084764102823101e-05
0.008375695906579494
2.105729618051555e-05
2.6672159947338514e-05
2.3620612410013564e-05
'''
========================================================
My environments:
PyTorch version: 1.7.1+cu110
Is debug build: False
CUDA used to build PyTorch: 11.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: Tesla V100-SXM2-32GB
GPU 1: Tesla V100-SXM2-32GB
GPU 2: Tesla V100-SXM2-32GB
GPU 3: Tesla V100-SXM2-32GB
Nvidia driver version: 450.51.06
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.20.1
[pip3] pytorch-msssim==0.2.0
[pip3] torch==1.7.1+cu110
[pip3] torchaudio==0.7.2
[pip3] torchvision==0.8.2+cu110
[conda] numpy 1.20.1 pypi_0 pypi
[conda] pytorch-msssim 0.2.0 pypi_0 pypi
[conda] torch 1.7.1+cu110 pypi_0 pypi
[conda] torchaudio 0.7.2 pypi_0 pypi
[conda] torchvision 0.8.2+cu110 pypi_0 pypi
