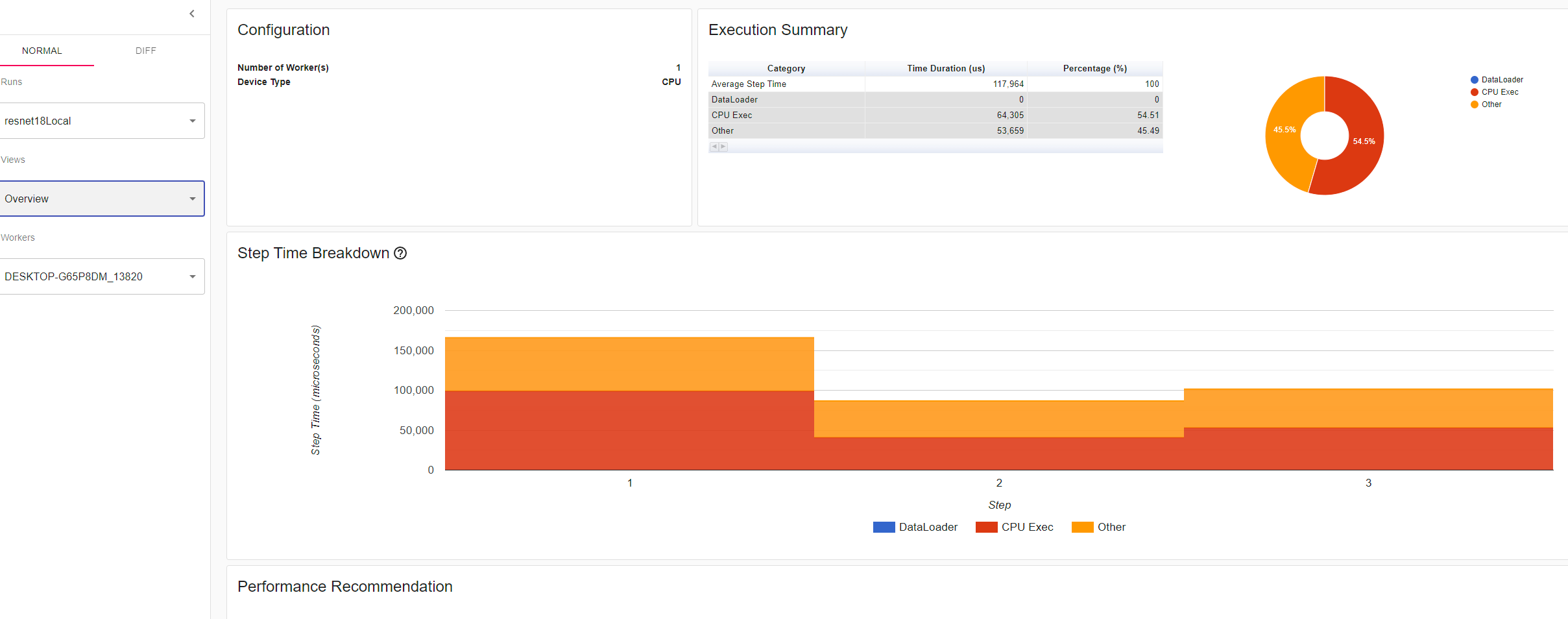
This answer helped me to get GPU recognized by the profiler with a side effect.
This command gets the “Distributed” view to appear, but the GPU is not recognized.
srun nsys profile --gpu-metrics-device=0 --sample=none --cpuctxsw=none --force-overwrite true --nic-metrics=true --trace=cuda,nvtx,cudnn --output=logs/${EXP_NAME}/nsys_logs_%h torchrun \
--nnodes $NUM_NODES \
--nproc_per_node 1 \
--rdzv_id $RANDOM \
--rdzv_backend c10d \
--rdzv_endpoint $MASTER_ADDR:$MASTER_PORT \
cifar10_with_resnset.py --epochs=10
While this command gets the “Distributed” view to diappear, and the GPU to be recognized.
torchrun \
--nnodes $NUM_NODES \
--nproc_per_node 1 \
--rdzv_id $RANDOM \
--rdzv_backend c10d \
--rdzv_endpoint $MASTER_ADDR:$MASTER_PORT \
cifar10_with_resnset.py --epochs=10
My PyTorch Code
import argparse
import torch
import torch.distributed as dist
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.cuda.amp import GradScaler, autocast
from torch.nn.parallel import DistributedDataParallel
from torch.utils import data
from torchvision import models
precisions = {
"fp16": torch.float16,
"fp32": torch.float32,
}
def train(train_sampler, epoch, device, train_loader, model, loss_criterion, optimizer, profiler, scaler, precision):
train_sampler.set_epoch(epoch)
model.train()
for batch_idx, (inputs, targets) in enumerate(train_loader):
profiler.step()
inputs, targets = inputs.cuda(device), targets.cuda(device)
optimizer.zero_grad()
with autocast(dtype=precision):
outputs = model(inputs)
loss = loss_criterion(outputs, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
if batch_idx % 10 == 0:
current_samples = batch_idx * len(inputs)
total_samples = len(train_sampler)
progress = 100.0 * current_samples / total_samples
print(f'Epoch: {epoch} [{current_samples}/{total_samples} ({progress:.0f}%)]\tLoss: {loss.item():.6f}')
def validate(epoch, device, validation_loader, model, loss_criterion):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for inputs, targets in validation_loader:
inputs, targets = inputs.cuda(device), targets.cuda(device)
outputs = model(inputs)
test_loss += loss_criterion(outputs, targets).item()
_, predicted = outputs.max(1)
correct += predicted.eq(targets).sum().item()
test_loss /= len(validation_loader.dataset)
accuracy = 100. * correct / len(validation_loader.dataset)
print(f'\nValidation. Epoch: {epoch}, Loss: {test_loss:.4f}, Accuracy: ({accuracy:.2f}%)\n')
def cleanup():
dist.destroy_process_group()
def get_data(rank, world_size, args):
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_sampler = data.distributed.DistributedSampler(train_set, num_replicas=world_size, rank=rank)
train_loader = data.DataLoader(train_set, sampler=train_sampler, batch_size=args.batch_size, num_workers=1,
persistent_workers=True)
validation_set = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
validation_loader = data.DataLoader(validation_set, batch_size=args.batch_size, num_workers=1,
persistent_workers=True)
return train_sampler, train_loader, validation_loader
def main(args, rank, world_size):
torch.manual_seed(0)
train_sampler, train_loader, validation_loader = get_data(rank, world_size, args)
device = torch.device("cuda:0")
print(f"Rank {rank}: Using CUDA device {device}")
model = models.resnet18(weights=None, num_classes=10)
model.conv1 = nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
model = model.cuda(device)
ddp_model = DistributedDataParallel(model)
scaler = GradScaler()
loss_criterion = nn.CrossEntropyLoss().cuda(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.001, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
print(torch.distributed.is_nccl_available())
print(torch.distributed.get_backend_config())
with torch.profiler.profile(
activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(wait=1, warmup=1, active=10, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler(f'./logs/{args.exp_name}'),
record_shapes=True,
profile_memory=True,
with_stack=True,
) as profiler:
for epoch in range(args.epochs):
train(train_sampler, epoch, device, train_loader, ddp_model, loss_criterion, optimizer, profiler, scaler,
precisions[args.precision])
validate(epoch, device, validation_loader, ddp_model, loss_criterion)
scheduler.step()
cleanup()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--epochs", type=int, default=10)
parser.add_argument("--batch-size", type=int, default=512)
parser.add_argument("--model", type=str, default="resnet18")
parser.add_argument("--precision", type=str, default="fp32")
parser.add_argument("--exp-name", type=str, default="test")
args = parser.parse_args()
# distributed
torch.distributed.init_process_group(backend='nccl', init_method='env://')
rank = torch.distributed.get_rank()
world_size = torch.distributed.get_world_size()
main(args, rank, world_size)