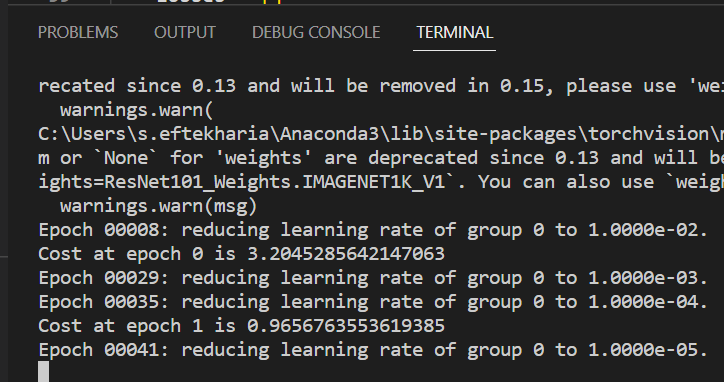
Hi
I am new to Pytorch. I used ReduceLROnPlateu and for some reason it starts reducing the learning rate way ahead of running the epochs. for Example I get the result below after running my code.
Does anyone know why such behavior can happen? or how to resolve?
Thanks
Could you post a minimal and executable code snippet reproducing the unexpected behavior, please?
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import os
import pandas as pd
import torchvision
from torch.utils.data import (Dataset,DataLoader)
from torch.utils.data import random_split
from Dataset_preparation_2 import CatDogDataset
#device setting
device= torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#Hyperparameters
in_channel=3
num_classes=2
learning_rate=0.01
batch_size=16
num_epochs=50
##load_model=True
train_transform = transforms.Compose([ transforms.Resize((224, 224)),
transforms.ToTensor()])
#Load Data
dataset=CatDogDataset(csv_file="Labels.csv",root_dir="C:/Users/s.eftekharia/Anaconda3/envs/py2/CatDog",transform=train_transform)
print(len(dataset))
train_set,test_set=torch.utils.data.random_split(dataset, [320,83])
train_loader=DataLoader(dataset=train_set,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(dataset=test_set, batch_size=batch_size, shuffle=True)
#test_set=DataLoader(dataset=test_set,batch_size=batch_size,shuffle=True)
#using resnet to mimick for training.
model=torchvision.models.resnet101(pretrained=True)
model.to(device)
#defining the Loss and Optimizer
Criterion=nn.CrossEntropyLoss()
Optimizer=optim.SGD(model.parameters(), lr=learning_rate)
#Implementing rate schedular
scheduler=optim.lr_scheduler.ReduceLROnPlateau(Optimizer,'min',factor=0.1,patience=5,verbose=True)
# Training the Network
for epoch in range(num_epochs):
losses = []
for batch_idx, (data, targets) in enumerate(train_loader):
# Get data to cuda if possible,
data = data.to(device=device)
targets = targets.to(device=device)
# forward
scores = model(data)
loss = Criterion(scores, targets)
losses.append(loss.item())
# backward
Optimizer.zero_grad()
loss.backward()
# gradient descent or adam step
Optimizer.step()
mean_loss=sum(losses)/len(losses)
scheduler.step(mean_loss)
print(f"Cost at epoch {epoch} is {sum(losses)/len(losses)}")
# Check accuracy on training to see how good our model is:
def check_accuracy(loader,model):
num_correct = 0
num_samples = 0
model.eval()
with torch.no_grad():
for x, y in loader:
x = x.to(device=device)
y = y.to(device=device)
scores = model(x)
_, predictions = scores.max(1) # one means in the dimension 1 or every row basiaclly.scores max
num_correct += (predictions == y).sum()
num_samples += predictions.size(0)
print(
f"Got {num_correct} / {num_samples} with accuracy {float(num_correct)/float(num_samples)*100:.2f}"
)
model.train()
print("Checking accuracy on Training Set")
check_accuracy(train_loader, model)
print("Checking accuracy on Test Set")
check_accuracy(test_loader, model)
#Saving Model
torch.save(model.state_dict(),"Model_number_"+str(epoch)+'.pt')