Hi,
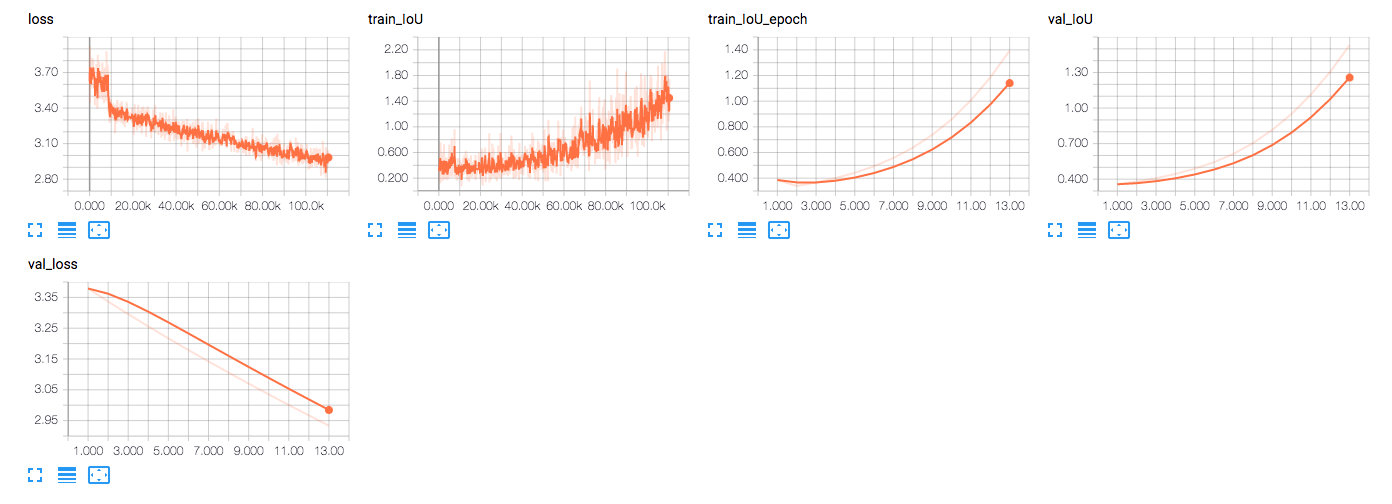
I’m trying to train FCN-32s in PyTorch, I follow this implementation in PyTorch [pytorch-fcn] to write my codes, and try to train FCN-32s with my wrapped API. However, the results are not so satisfied, in the pytorch-fcn, it reports results after 90K iterations achieving 63.13 IU, but in my implementation, even after 100K iterations, the results are still very bad.
Results in tensorboard(after 100K iterations):
My implementation codes:
Codes
# modesl.py
def get_upsampling_weight(in_channels, out_channels, kernel_size):
"""Make a 2D bilinear kernel suitable for upsampling"""
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:kernel_size, :kernel_size]
filt = (1 - abs(og[0] - center) / factor) * \
(1 - abs(og[1] - center) / factor)
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size),
dtype=np.float64)
weight[range(in_channels), range(out_channels), :, :] = filt
return torch.from_numpy(weight).float()
class FCN32s(nn.Module):
def __init__(self, pretrained=False, num_classes=21):
super(FCN32s, self).__init__()
# vgg16 = VGG16(pretrained=True)
vgg16 = VGG16(pretrained=False)
if pretrained:
state_dict = torch.load('./vgg16_from_caffe.pth')
vgg16.load_state_dict(state_dict)
self.features = vgg16.features
self.features._modules['0'].padding = (100, 100)
for module in self.features.modules():
if isinstance(module, nn.MaxPool2d):
module.ceil_mode = True
# Fully Connected 6 -> Fully Convolution
self.fc6 = nn.Conv2d(512, 4096, 7)
self.relu6 = nn.ReLU(inplace=True)
self.drop6 = nn.Dropout2d()
# FC 7
self.fc7 = nn.Conv2d(4096, 4096, 1)
self.relu7 = nn.ReLU(inplace=True)
self.drop7 = nn.Dropout2d()
self.score = nn.Conv2d(4096, num_classes, 1)
self.upsample = nn.ConvTranspose2d(
num_classes, num_classes, 64, 32, bias=False)
# Init ConvTranspose2d
init_weights = get_upsampling_weight(num_classes, num_classes, 64)
self.upsample.weight.data.copy_(init_weights)
# Init FC6 and FC7
classifier = vgg16.classifier
for idx, l in zip((0, 3), ('fc6', 'fc7')):
layer = getattr(self, l)
vgg16_layer = classifier[idx]
layer.weight.data = vgg16_layer.weight.data.view(
layer.weight.size())
layer.bias.data = vgg16_layer.bias.data.view(
layer.bias.size())
def forward(self, x):
w, h = x.size()[2:]
x = self.features(x)
x = self.drop6(self.relu6(self.fc6(x)))
x = self.drop7(self.relu7(self.fc7(x)))
x = self.score(x)
x = self.upsample(x)
x = x[:, :, 19:19+w, 19:19+h].contiguous()
return x
# datasets.py
def gen_voc_dataset(phase, path='/share/datasets/VOCdevkit/VOC2012'):
# VOC Dataset
voc_input_trans = T.Compose([
ToTensor(rescale=False), # Just ToTensor with no [0, 255] to [0, 1]
IndexSwap(0, [2, 1, 0]), # RGB --> BGR
T.Normalize(
VOCClassSegmentation.mean_bgr,
(1, 1, 1)),
])
voc_target_trans = ToArray()
dataset = VOCClassSegmentation(
path, phase,
input_trans=voc_input_trans, target_trans=voc_target_trans)
return dataset
def gen_sbd_dataset(phase, path='/share/datasets/SBD/dataset'):
sbd_input_trans = T.Compose([
ToTensor(rescale=False),
IndexSwap(0, [2, 1, 0]),
T.Normalize(
SBDClassSegmentation.mean_bgr,
(1, 1, 1)),
])
sbd_target_trans = ToArray()
dataset = SBDClassSegmentation(
path, phase,
input_trans=sbd_input_trans, target_trans=sbd_target_trans)
return dataset
def make_dataset(phase, ignores=None):
datasets = []
if ignores is None:
ignores = []
ignores = set(ignores)
for key, val in globals().items():
if key.startswith('gen_'):
dataset_name = key.split('_')[1]
if dataset_name not in ignores:
print('Use dataset {} for phase {}'.format(dataset_name, phase))
d = val(phase)
datasets.append(d)
dataset = ConcatDataset(datasets)
return dataset
# utils.py
def get_params(model, bias=False):
for m in model.modules():
if isinstance(m, nn.Conv2d):
if bias:
yield m.bias
else:
yield m.weight
# loss.py
class CrossEntropyLoss2d(nn.Module):
def __init__(self, weight=None, size_average=True, ignore_index=255):
super(CrossEntropyLoss2d, self).__init__()
self.nll_loss = nn.NLLLoss2d(weight, size_average, ignore_index)
def forward(self, inputs, targets):
return self.nll_loss(F.log_softmax(inputs), targets)
# train.py
import argparse
import torch.optim as optim
import torch.nn as nn
from torch.utils.data import DataLoader
from torchtools.trainer import ModelTrainer
from torchtools.callbacks import ModelCheckPoint
from torchtools.callbacks import TensorBoardLogger
from torchtools.meters import FixSizeLossMeter, EpochLossMeter
from torchtools.meters import EpochIoUMeter, BatchIoUMeter, FixSizeIoUMeter
from torchtools.meters import SemSegVisualizer
from torchtools.loss import CrossEntropyLoss2d
from datasets import make_dataset
from model import FCN32s as Model
from utils import get_params
parser = argparse.ArgumentParser()
parser.add_argument('--EPOCHS', type=int, default=200)
parser.add_argument('--BATCH_SIZE', type=int, default=1)
parser.add_argument('--LR_RATE', type=float, default=1e-10)
parser.add_argument('--MOMENTUM', type=float, default=0.99)
parser.add_argument('--WEIGHT_DECAY', type=float, default=5e-4)
parser.add_argument('--NUM_WORKERS', type=int, default=4)
parser.add_argument('--OUTPUT_PATH', type=str,
default='./outputs')
parser.add_argument('--PIN_MEMORY', type=bool, default=True)
parser.add_argument('--SHUFFLE', type=bool, default=True)
parser.add_argument('--DEVICE_ID', type=int, default=0)
parser.add_argument('--USE_CUDA', type=bool, default=True)
parser.add_argument('--DATA_PARALLEL', type=bool, default=False)
args = parser.parse_args()
train_set = make_dataset('train', ignores=['voc'])
val_set = make_dataset('val', ignores=['sbd'])
train_loader = DataLoader(train_set, args.BATCH_SIZE, shuffle=args.SHUFFLE,
num_workers=args.NUM_WORKERS,
pin_memory=args.PIN_MEMORY)
val_loader = DataLoader(val_set, args.BATCH_SIZE, shuffle=args.SHUFFLE,
num_workers=args.NUM_WORKERS,
pin_memory=args.PIN_MEMORY)
model = Model(pretrained=True)
criterion = CrossEntropyLoss2d()
if args.USE_CUDA:
model = model.cuda(args.DEVICE_ID)
criterion = criterion.cuda(args.DEVICE_ID)
if args.DATA_PARALLEL:
model = nn.DataParallel(model)
optimizer = optim.SGD([
{'params': get_params(model, bias=False)},
{'params': get_params(model, bias=True), 'lr': args.LR_RATE * 2,
'weight_decay': 0},
],
lr=args.LR_RATE, momentum=args.MOMENTUM, weight_decay=args.WEIGHT_DECAY)
trainer = ModelTrainer(model, train_loader, criterion, optimizer, val_loader,
use_cuda=args.USE_CUDA, device_id=args.DEVICE_ID)
checkpoint = ModelCheckPoint(args.OUTPUT_PATH, 'val_loss', save_best_only=True)
train_loss_meter = FixSizeLossMeter('loss', 'train', 20)
val_loss_meter = EpochLossMeter('val_loss', 'validate')
val_iou_meter = EpochIoUMeter('val_IoU', 'validate', num_classes=21)
train_iou_meter = FixSizeIoUMeter('train_IoU', 'train', 20, num_classes=21)
train_epoch_iou_meter = EpochIoUMeter('train_IoU_epoch', 'train',
num_classes=21)
ss_visualizer = SemSegVisualizer('Prediction', 'train', 'voc',
300 // args.BATCH_SIZE)
tb_logger = TensorBoardLogger(args.OUTPUT_PATH)
trainer.register_hooks([train_loss_meter, val_loss_meter, ss_visualizer,
checkpoint, val_iou_meter, train_iou_meter,
train_epoch_iou_meter, tb_logger])
trainer.train(args.EPOCHS)
Could someone give me some hints with my errors ![]()
![]() ? Thanks.
? Thanks.