Hi everyone! I’m working on a classification problem where I have a folder with images and the label is the folder name. I am using the following script to generate loaders but when I iterate through any of the two loaders, I do not get random samples. Rather, its all samples from the first class (observed by printing the labels). The pytorch version is 0.4.1.post2 (Ubuntu).
The dataloader I use is standard from pytorch. You can import it with torch.utils.data. DataLoader.
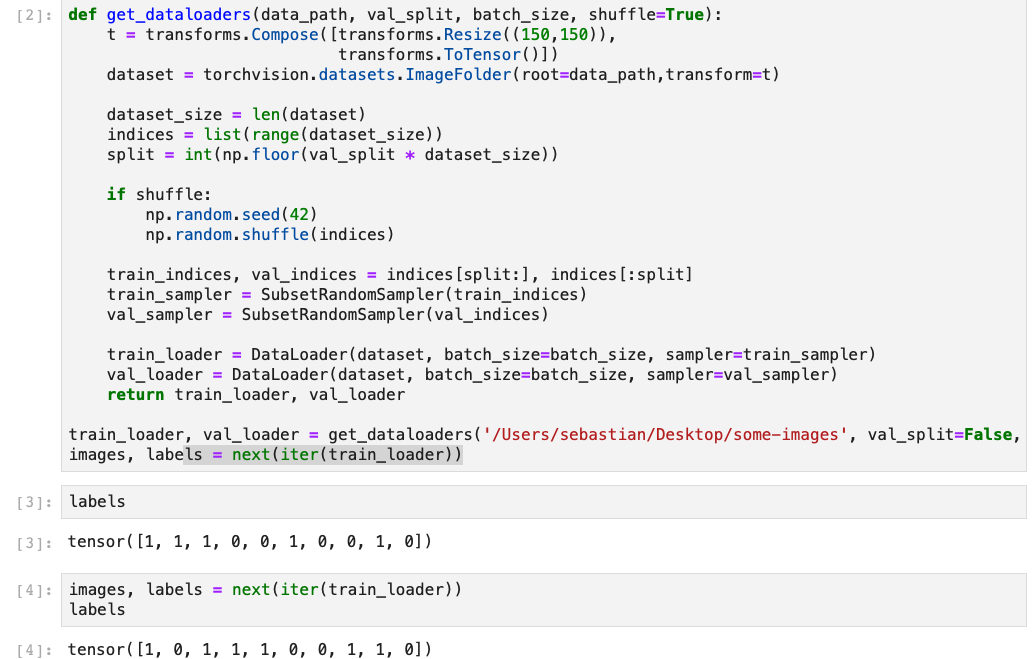
It’s possible to give this a try with some dummy data organised with the folder structure that I mentioned. The output I see is that it is the same class in each batch of images as I iterate with next(iter(train_loader)); if you see the same class label with my dataloader script on some other dataset, then it is the same issue.
Thanks so much for your efforts!
This is really strange - my setup is Ubuntu 16.04, Python3.5, torch 1.0.1.post2. Could you share your setup details? I’ve tried this on 3 other different machines with the same results x_x
Okay - I’m in the processing of creating some new environments so will update you in a few. Could you lastly share the full call to the get_dataloaders function? It seems you are not using the val_split command which is the whole point of me using SubsetRandomSampler.
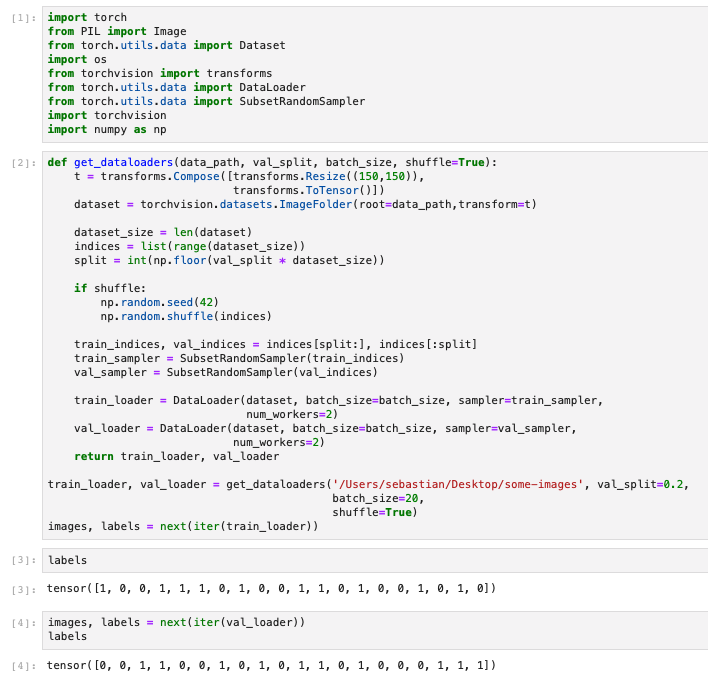
I tried it on both my laptop (screenshot from above) and on my Ubuntu machine (which has the cuda version of PyTorch). It seems to work in both cases. Regarding the val_loader, just enabled it:
hmm, this is super annoying! I think I will have to resort to making my own Dataset class like your example but since ImageFolder was built for this, I was hoping to get away with inbuilt functionality.
I HAVE SOLVED MY STUPID ISSUE!
my folder structure had an extra folder before the classes and so the entire dataset had only one label.
I’ll be killing myself now - thanks a bunch @rasbt
np.random.shuffle is done before the data splitting to create datasets with randomly shuffled input samples.
The DataLoader itself makes sure that the sample of each batch are shuffled.