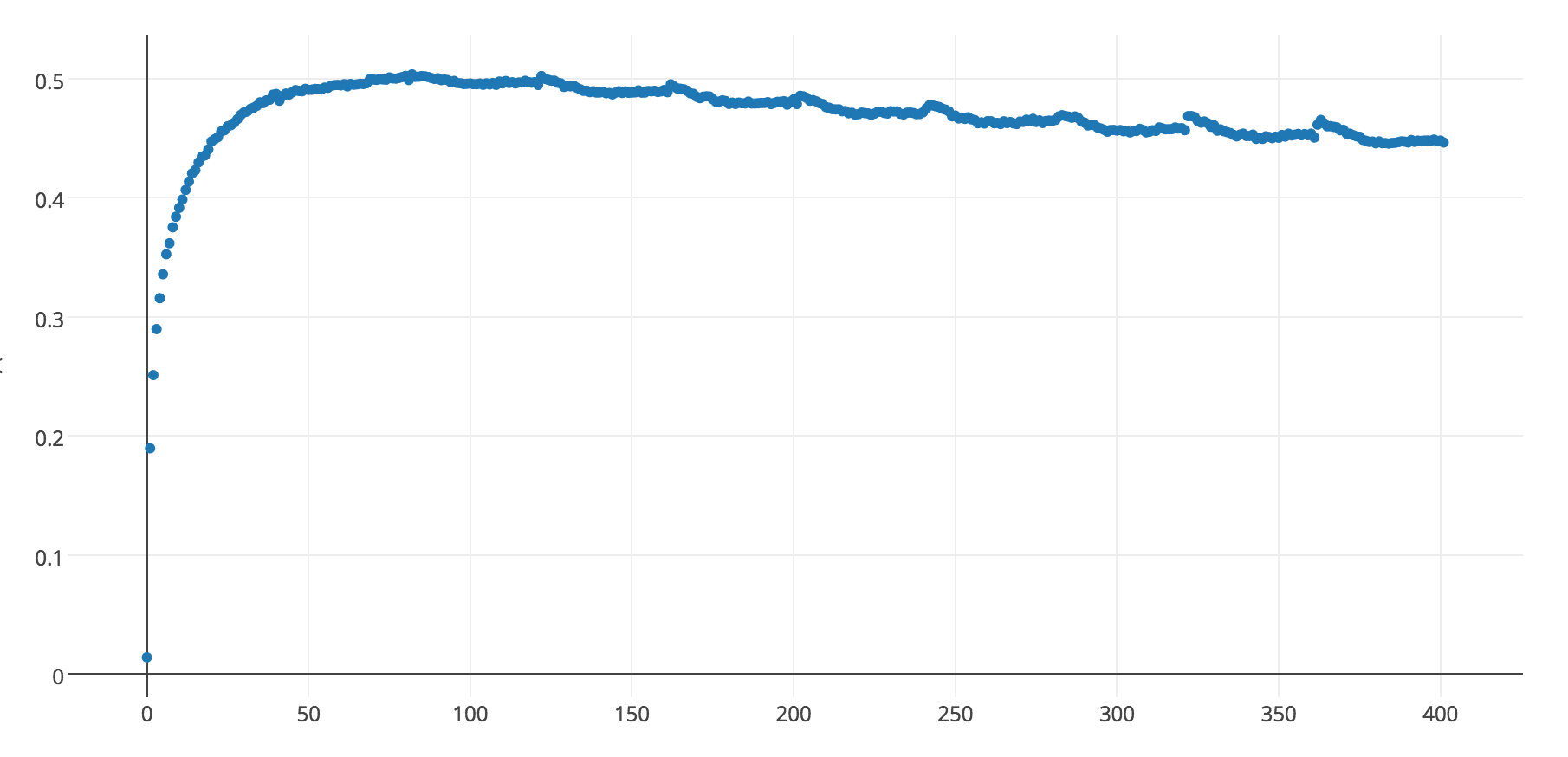
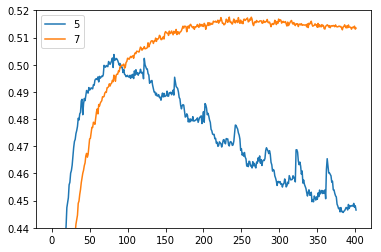
I recently used pytorch to implement a CNN for text classification. My validation accuracy looks weird that there are peaks appearing at the beginning of each epoch, which I didn’t observe in my tensorflow implementation.
I’m admitting that you are not randomising the validation set (sample wise or batch wise) when you score your model after each epoch. Therefore, you should probably have somewhat easier examples that your model can express better art the beginning of each epoch.
it is fairly common to experience some repetitive patterns in the training and/or validation loss if you keep the order of your sets throughout the train. I think you should not worry about this, as your model seems to be learning something.