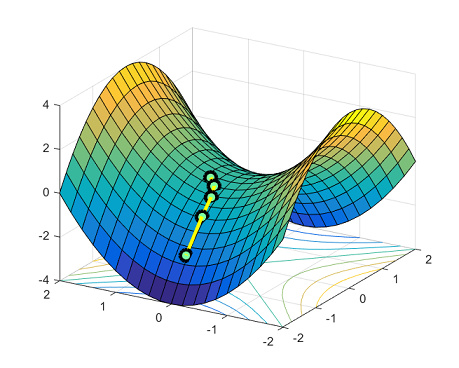
While training, I logged the MSE computed on whole dataset at each epoch. The weird thing is that there is a flat region in the training curve. It seems that my network got stuck and learned nothing from epoch 2 to epoch 10. Then it got a ‘Aha moment’ at around epoch 11 and the loss dropped rapidly.
This really puzzled me. Any idea why this happened?
Yeah, this makes sense. But I tried to repeat the training process several times and kept getting exactly similar ‘flat region’. Since dataset are randomly shuffled by DataLoader, it shouldn’t get into the saddle point every time, right?
Or is this phenomenon caused by some intrinsic nature of the model / dataset used?