Hello Guys,
i want to research the impact of diffrent Data-Augmentation-Techniques for STT-Models. For this im Using a Pretrained (Wav2Vec2) Model trained on CommonVoice. If i want to test the impact of augmenting the Data by 1) adding a completely new dataset 2) adverserial attack 3) maybe trying TTS-synthesized data
What should i validate the Modell against while Training? For my final comparison i want to use the Test-Split of CommonVoice, but can i just reuse that Dataset for my Validation Step (while Training) or should i use a split what ever im training on?
Since English is not my native language, I’ll try to explain my problem via a graphic.:
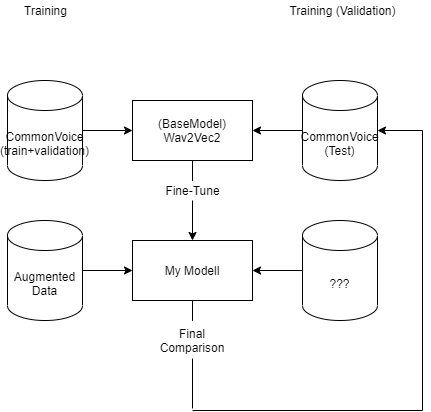
I am using a pre-trained Wav2Vec2 model and would like to train it further with “Augmented Data”. So for example by taking either a complete new dataset, by TTS syntesized data or by Adverserial Attack based on CommonVoice training data.
I will compare the augmentation methods later using that of the Common Voice -test split. Now, when I train my models, what should I validate them on during training? Should I just split the new (augmented) training data into 80% training 20% validation, or should I take 100% of the augmented data and validate on Common Voice - test split? Is it problematic during training and final comparison to validate the systems with the same dataset-split (as seen in the graph (see dataset above right)
ty in advcaned