HI all:
when I compare the inference time cost between libtorch(c++) and torchscript(python),with LaneGCN network,I found that c++ inference time more slow than python, I have no idea about that.
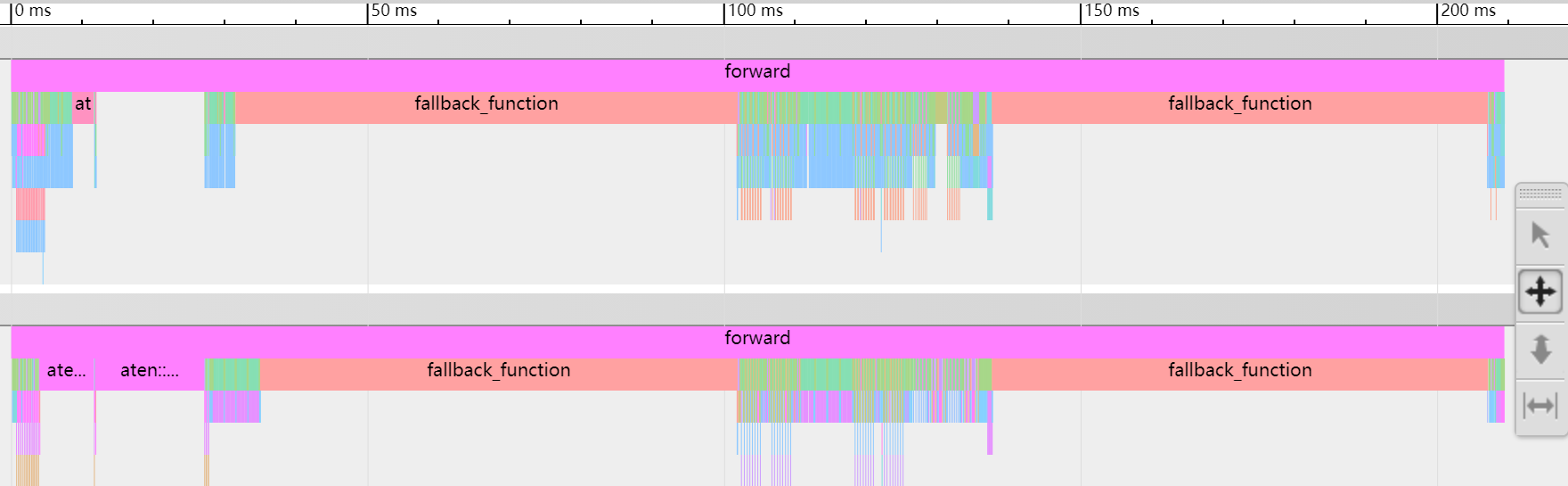
actually, when compare torchscript with the original ckpt model, torchscript inference sometimes run more slower than ckpt inference, when I use torch.autograd.profiler.profile to debug these slower time point, I got this pictual below:
Hi @johnnylee ,
have found the root cause of your issue and a fix for it? I am observing the same issue when using a torchscript created from a stock pretrained faster rcnn.
Thx, T.
To also answer the original question: The fallback_function is a function inserted by the PyTorch JIT profiling executor for cases when its optimization assumptions fail. And that probably is the part of the problem with the performance, too…
So as described in the issue disabling the JIT profiling executor / tensor expression fuser one way or the other helps.