I was chatting in the slack forum and Soumith who was very kind to help me. However, there was something I still didn’t quite understand and thought it would be helpful to share and ask in more detail.
My main question is how mathematically the gradients are propagated through reassignment expressions, like:
w[:,1] = v
and how their derivatives look like or if they are at all considered operations that back propagation goes through. Does back propagation go through this? If it does what does it mean precisely Mathematically)? Does the “assignment” operation become part of the computation graph or is it just a convenient way to move numbers around?
For example if we have:
import torch
from torch.autograd import Variable
x = Variable(torch.rand(2,1),requires_grad=False) #data set
w = Variable(torch.rand(2,2),requires_grad=True) #first layer
v = Variable(torch.rand(2,2),requires_grad=True) #last layer
w[:,1] = v[:,0]
r = w
m = torch.matmul(w,x)
y = torch.matmul(v, m )
if I were to do y.backward() what happens? Does it consider the “cycle” in the computation graph or does it just consider the assignment as putting new numbers (not relating to previous numbers)?
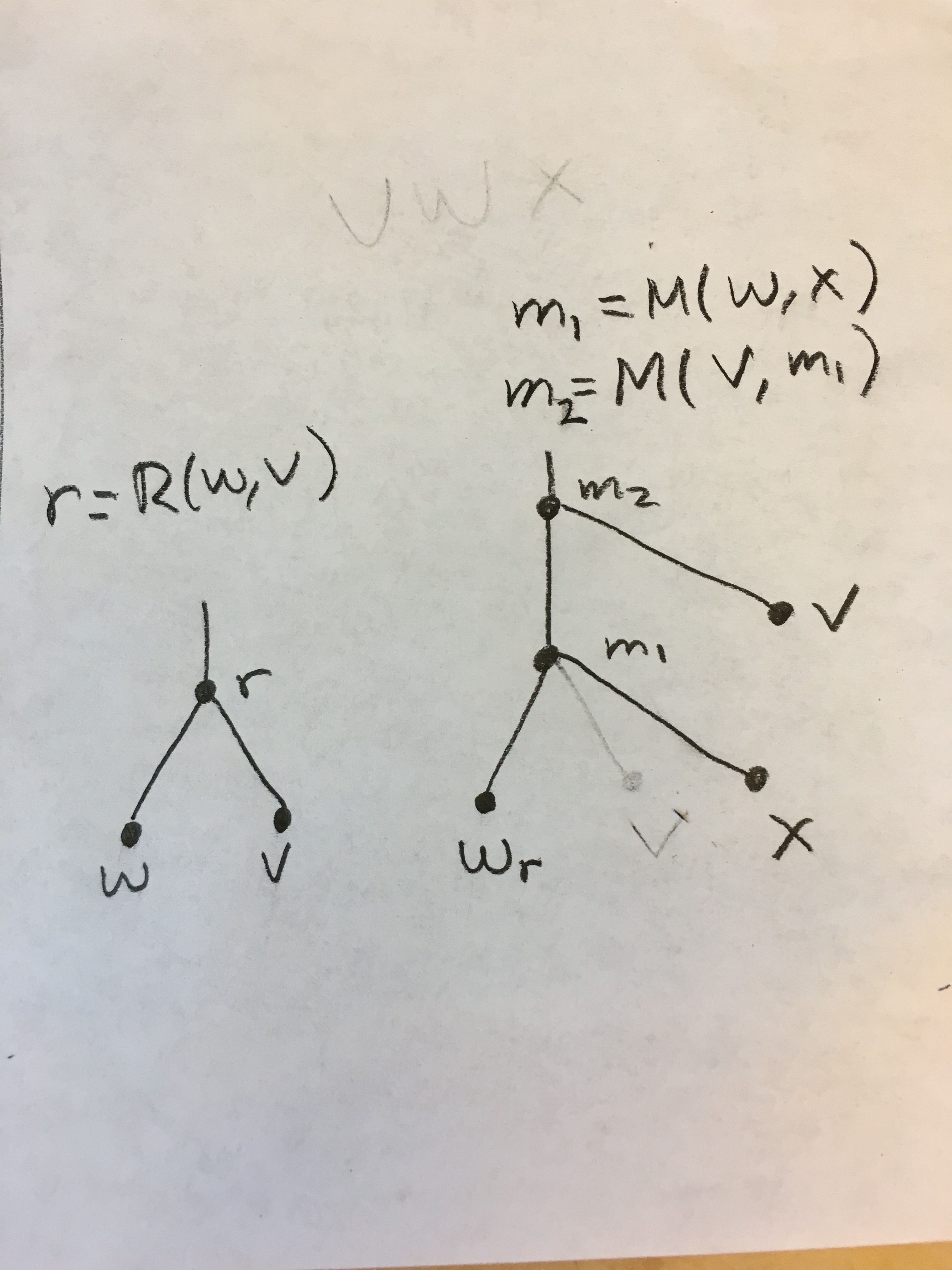
I guess I’m asking if this is what the computation (and thus backward pass) graph look like or if the assignment is not considered in the backprop:

the nodes are variables and R returns the re-assigned variable and M is for matrix multiplication.
Or is the following correct (note different graphs means back prop does not connect the different computation graphs):