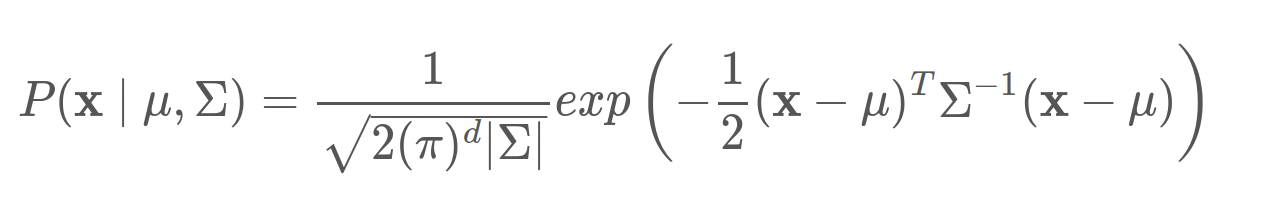But after digging into the torch.distributions.MultivariateNormal(loc, cov).sample() source code it looks like it is essentially just taking the Cholesky Decomposition of the covariance, doing a torch.matmul of the Cholesky by a random 1D array the length of the Cholesky and adding the loc.
Since my Statistics isn’t what it should be can you please explain why this is a Multivariate Normal Distribution? What is the equation for this? What is my equation? They definitely are not the same thing.
The random 1d array is a vector of independently sampled normal variates
(with mean zero and standard deviation one). That is the same as saying
that it is a single sample from a multidimensional (with the number of
dimensions equal to the length of the array) spherically-symmetrical
multivariate normal distribution centered at the origin (multidimensional
mean of zero) with its covariance matrix equal to the identity matrix (that
is, standard deviations of one and no cross-correlations).
So we start with a multivariate normal distribution, but one with a special
form.
The Cholesky decomposition of the input covariance matrix is, morally
speaking, its “square root.” Just as you would multiply a single normal
deviate (with standard deviation one) with the square-root of a desired
variance to produce a gaussian deviate with that desired variance, we
multiply the sample from the multivariate normal distribution with covariance
equal to the identity matrix with the square root of the desired covariance
matrix.
This resulting multidimensional sample still has a (multidimensional) mean
of zero. Just as we would do in the one-dimensional case, we add to that
sample the desired (multidimensional) mean to get the final sample.
This is the standard algorithm for generating samples from a multivariate
gaussian distribution. Note, you only have to perform the Cholesky
decomposition once (and then reuse it), even if you generate a lot of
samples.