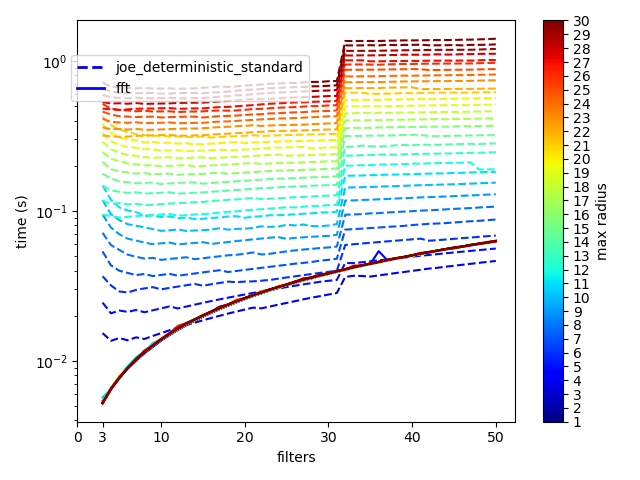
this is a plot of runtime vs number of filters (n_bins) and kernel width (max_sigma) in a Conv2d layer. what happens at 33 filters? obviously a different convolution strategy is being chosen for some optimization reason but does anyone know exactly what the switch is and where it happens in the code?
If you disable cudnn, you should use only our implementation and should not see this jump
cudnn has it’s custom algorithms depending on the input size
You can enable cudnn benchmark (torch.backends.cudnn.benchmark=True) and see if you see better behavior, it should pick the best algorithm and so remove such artifacts.
i’m guessing there’s no way to find out what cudnn is doing because it’s closed source? or is there a way to get nvprof (or something like that) to tell me which conv strategy it’s using?
Yes, you can use nvprof to find out which convolution algorithm was used.
On your gpu machine: nvprof -o prof.nvvp python train_mnist.py
Then copy the prof.nvvp to your local machine and run: nvvp prof.nvvp
More details can be found here: https://gist.github.com/sonots/5abc0bccec2010ac69ff74788b265086
Indeed, it seem like a change in the convolution algorithm. By the way, you cannot select/check which convolution is used in PyTorch, as far as I know. Could anybody confirm that or give some more details how to do it? Moreover, there is an optimizer run by NVidia to select the most optimal convolution algorithm, and sometimes the optimizer tests a few convolutions before making the final choice, see: https://arxiv.org/pdf/1602.08124.pdf You can also control which convolution algorithm is used on the CUDA level: http://www.goldsborough.me/cuda/ml/cudnn/c++/2017/10/01/14-37-23-convolutions_with_cudnn/
Yes pytorch uses the default algorithm if you do nothing. (and you can’t specify it directly).
If you set torch.backends.cudnn.deterministic it will use the default deterministic algorithm.
And if you set torch.backends.cudnn.benchmark it will try different algorithm to pick the best one.
Could you post the conv setup as well as the input, which would reproduce this error?
Also, I would recommend to update to the latest stable version (or nightly), as it’ll include the latest bug fixes (besides new features)
it’s quite hard to give you a MWE because of how involved the code is. I have a conda env and script here
i suspect it’s a memory leak because if i make shorter runs (i’m iterating over a set of hyperparameters) then there is no segfault. is it possible to use something like valgrind to investigate this?
also btw @albanD setting torch.backends.cudnn.deterministic = True did not actually fix the convolution strategy (i.e. force a fixed strategy); here is what i see
edit: @Adam_Dziedzic i also can’t see which cuda conv strategy is being used after running nvprof. only thing i can see is implicit_sgemm.
For cudnn.deterministic = TrueCUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM will be used in the forward pass.
Given that the code includes multiple files, I would recommend to first disable the multiprocessing.pool, and try to remove everything unnecessary until you could narrow down the segmentation fault to a single model with some dummy data.
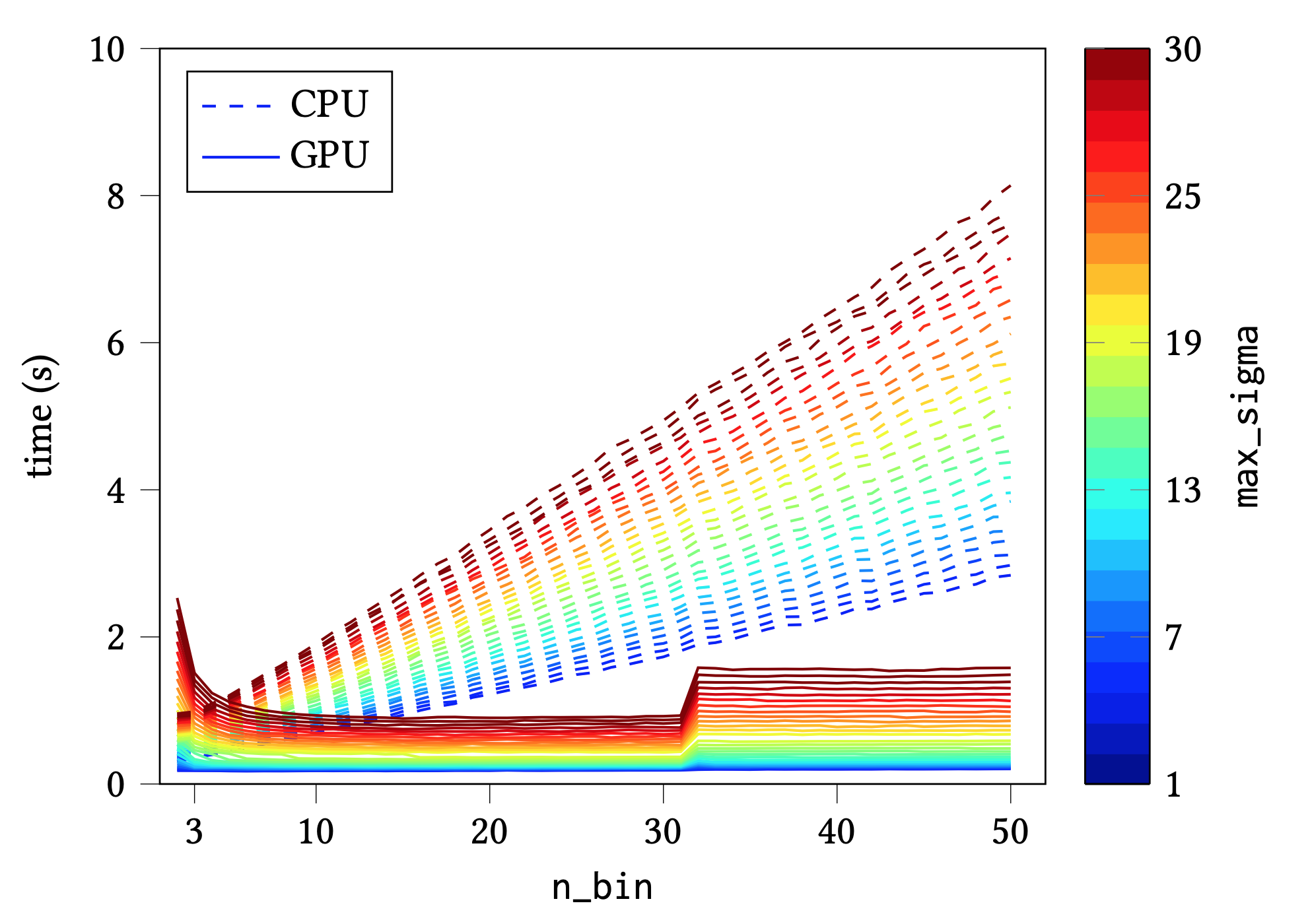

 I am pretty sure we would be happy to accept a PR adding this !
I am pretty sure we would be happy to accept a PR adding this !