My goal is to detect manufacturers on images. Most of time they are presented by logo + text label name and less often only by one of these. Most of them I can detect them with ocr as they often have good readable (for ocr) manufacturer names but from time to time I meet text labels having curly letters.
So the question is exactly about the latter case.
If I have a logo and a text label with curly letters should I add to dataset only logos or logos+label names?
I ask this question because I assume that logos+names have more size but probably it may be hard for network to distinguish words while only logos are more different from each other but small in size.
For example I have the following item.
Which labeling method is better in relation to network detection stability?
I think you should try out both approaches and check which one works best for your specific use case.
My guess would be that the logo + text crop could work better, as the text also provides a lot of features the CNN should be able to extract.
Thank you for your opinion.
Two more related questions for which I would like to hear your guesses if possible:
I.
For example the above manufacturer (e.g. class A) can be represented by
only logo;
only text label;
logo + text;
So we have images of the category with all three possible variations.
Accordingly the three cases above we crop following areas:
logo as class A;
text as class A;
could we crop logo+text as class A or we should crop the logo as class A and the text as class A apart getting two bounding boxes?
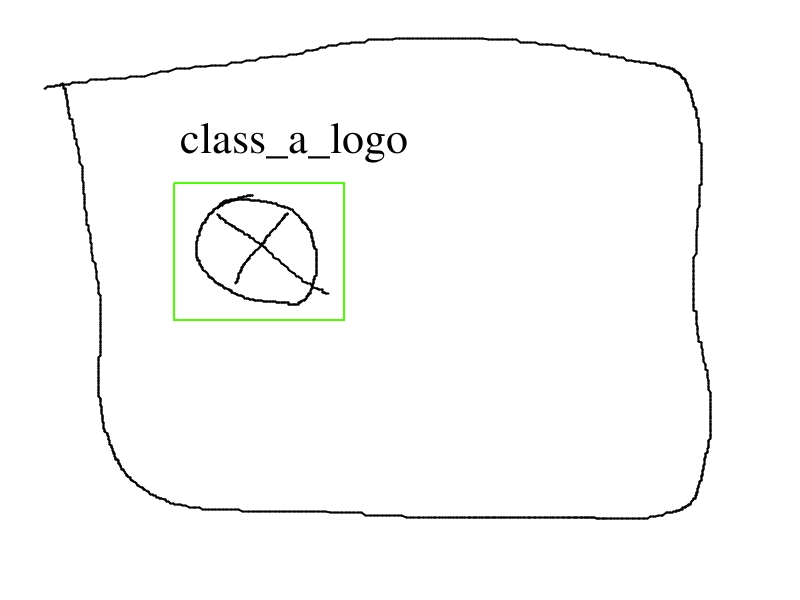
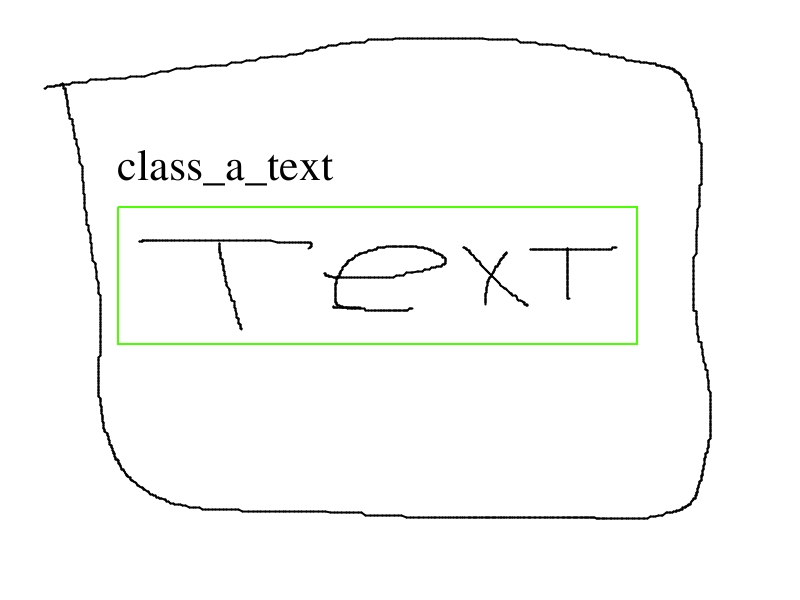
In case I express myself incomprehensibly: If for specified category we have two representation (logo and text) and in case we have only one of them we label only it itself so what we should do when these representations are next to each other - keep labeling them separately or combine them or we have to have only one representation for class and thus create two categories (for example class_A_logo and class_A_text)?
II.
If your answer on the previous question that we should combine near positioned boxes into one then there’s one more question?
Logo+text can be positioned in different ways (next to each other or one under one).
Does cnn translation invariance ability cope that difference in positioning?
It depends a bit on your current workflow. If you are detecting the logo and (logo + ) text separately, are you passing them to the same model or are you using a “logo” and another “text” model?
In the former case (one model only), you could try to detect overlapping bounding boxes or ones, which are close to each other, and let the same model create multiple predictions, which can then be either used to calculate the (weighted) prediction.
This workflow would of course be a bit more complicated than using a single input, so in case you would like to start simple (which I would recommend to do), you could try to use the largest box, which should include the logo + text, if possible.
In that more simple case let’s say we crop box containing logo+text if they are present but can we crop boxes containing only logo or text or the point is to crop only their combined combination?
In my “simple” use case I describe a single crop, so that a single model would also get only one input and predict the class.
If you have multiple crops, you would have to think about how multiple crops of the same image should be treated:
single model with multiple forward passes → prediction is a weighted mean?
multiple models → would this work for the use case or are the crops imbalanced and one model might not be trained enough
I might be mistaken, but in the standard use case each target bounding box would represent a different object. I.e. while the class might be the same (e.g. two persons), the objects themselves would not be the same.
In your use case, however, the logo and text would both represent the same object and class.
I just wanted to point out to the case, where the model could predict classA for the logo and classB for the text. What would you do in such a case, i.e. what would the prediction be?
It’s totally fine to represent different bboxes as different objects. The problem of identifying of object by its parts (logo, text) is out of scope of our topic)
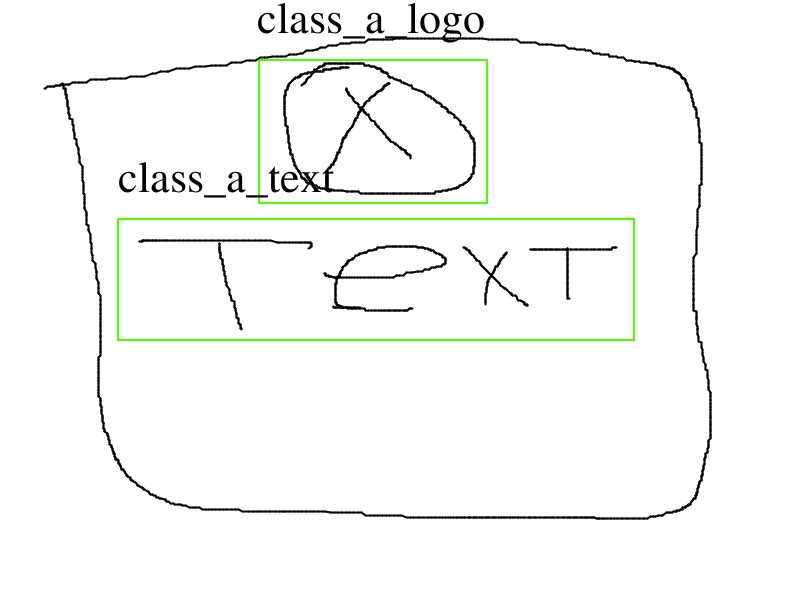
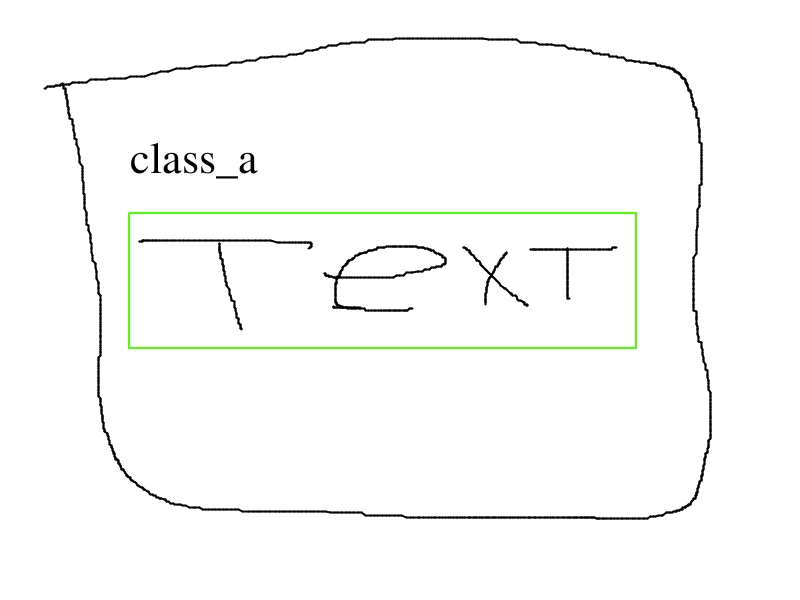
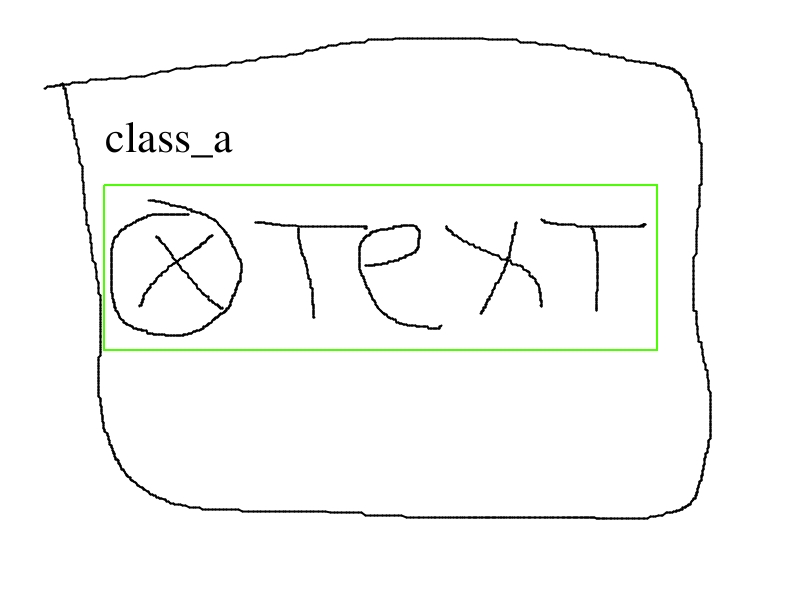
The initial question in visual way:
For example we’ve got four images representing one class.
Third and fourth images are combinations of the first two. there can be much more such combinations.
The question is which labeling way is preffered?
At the time I lean towards the first case as it is universal while the second might be a bad idea because in one case we label only the logo as class_a, in the other case logo+text as class_a.
I think this might “confuse” our model.
Аfter all this i just would like to hear your opinion on the above)