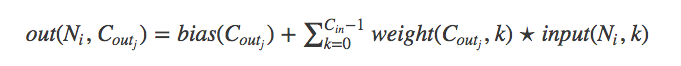If we have say a 1D array of size 1 by D and we want to convolv it with a F=3 filters of size K=2 say and not skipping any value (i.e. stride=1), would the code be:
F,K=3,2
m = nn.Conv1d(1, F, K, stride=1)
I am just not sure when the in_channels would not be 1 for a 1D convolution. Furthermore, assuming it is possible for it to not be 1, does it mean when its not one? Is it not 1 when there are lots of 1D strips we are considering, say in a data set of size N (though not sure what that type of data set would mean…)
You could stack different time signals together and thus create one time signal with multiple channels. Imaging EEG data filtered with different bandpasses. You could create a signal for each band, concat these signals and convolve through the time dimension using all input channels.
It’s comparable to the color channels of an image.
I hope it makes sense to you
if one did that would nn.Conv1d(1, F, K, stride=1) combine the output of each filer? I guess it would based on the equation:
which I find super strange. What would the meaning of combining the processing of one data point to another? Isn’t that weird? Maybe its not but I don’t understand the motivation to do it.
Each filter in the conv layer would convolve over the input signal using its kernel size F and all input channels.
Assuming the kernel size is 3 and the input signal has 5 channels, each filter will have 3*5=15 weights and a bias.
I don’t really understand your question regarding the processing of one data point to another.
Another example could be temperature and humidity measurements.
e.g.
at 9am: temp 10°, humidity 60%
at 10am: temp 13°, humidity 57%
Each point in time would have two values. In this example the input data has two channels.
With kernel 2 and stride 1, the convolution will look at successive pairs of timestep, looking at two values for each timestep because there are two channels.
If you specify 3 output channels then the conv1d will be applied 3 times to the input with 3 different sets of weights, and produce 3 output values per timestep.
Stereo audio when you don’t want to sum the channels. There has been some good results with neural networks that use the two channels (microphones setup in different parts of the room) to determine background noise vs speech and filter it out.
Is there a case where 2dCNN should be used instead of 1dCNN? Like what are some examples of the dataset with more than 1 channels but then 2dCNN would perform better compared to 1dCNN? Will the channels being combined (treated as a whole) during training?For example, the data I am working with is the phase waveforms for circuit and I am using 1dCNN, but the generalization of the model is not that well. I am not sure if it is because the model overfits or it cannot extract major features.
Inputs with spatial dimensions are usually applied to 2D conv layers, since the kernels would perform the convolution in both spatial dimension (e.g. height and width of an image).
So is the 2dCNN extract the spatial relationships within each channel? So a convolution layer learns “filters” to figure out spatial patterns in the image across its colour channels? My question is, aren’t multi-channel 1dCNN also can extract the spatial relationships within each channel? Or how does 1dCNN work for multi-channel data? Does it relate each channel together or extract patterns separately within each channel?
Because I want to capture the one channel signal drop compared to the other channels, I need to capture the dropping pattern and the correlation between all channels. But I am not sure which CNN can be a best fit. Intuitively, I should have used 1dCNN, but then for 2dCNN, I can also let the colour channel be the number of signal channels, and then capture the spatial patterns.
Both, nn.Conv1d and nn.Conv2d, will use all the input channels in each filter to create a single output map (or output channel). E.g. if you are defining a conv layer as nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3) each of the 16 filters will use all 3 input channel to create a single output channel. These output channels are then stacked to create an activation map with 16 channels. The kernel size defines the spatial size of the kernel as described before.
I don’t understand this use case as it seems you want to use each input channel separately (in which case you would use a depthwise convolution via the groups argument) but then you also want to see correlation between channels.
Thank you for your responses, I really appreciated.
Let me try to clarify the questions. So for example, I have 3 signals which are in similar waveforms with respect to time. I want to capture the case of where one drops significantly compared to the other two. So, aren’t this equivalent to capturing the correlation between all 3 channels? Basically, my question is to verify whether 1dCNN can help me to capture the dropping phenomenon I want to detect.
Indeed, nn.Conv1d layers can be applied to your use case with temporal signals. Since you want to process the information of all 3 channels, a standard conv layer using all input channels sounds also correct.