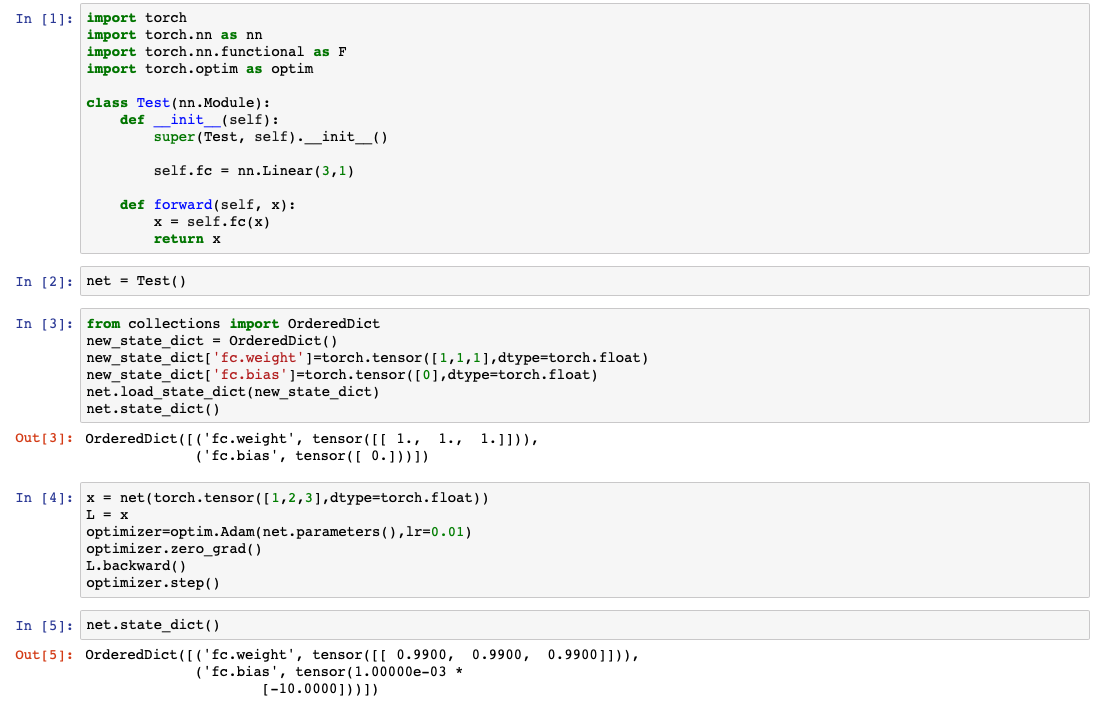
Hello,
I met a problem when using backward() to do backpropagation. The something strange came.
I define a simple network with only 1 linear layer nn.Linear(3,1) and used load_state_dict to set the weights to be [1,1,1] and bias [0].
Then I passed
x = net(torch.tensor([1,2,3],dtype=torch.float))
L = x
L.backward()
Then I used optim.step() to update the weights and found that all weights changed by 0.01 (my learning rate). Should not the weights get updated differently? I got confused…
Here is a screen shot: