what is gain value in nn.init.calculate_gain(nonlinearity, param=None) and how to use these gain number and why ?
1 Like
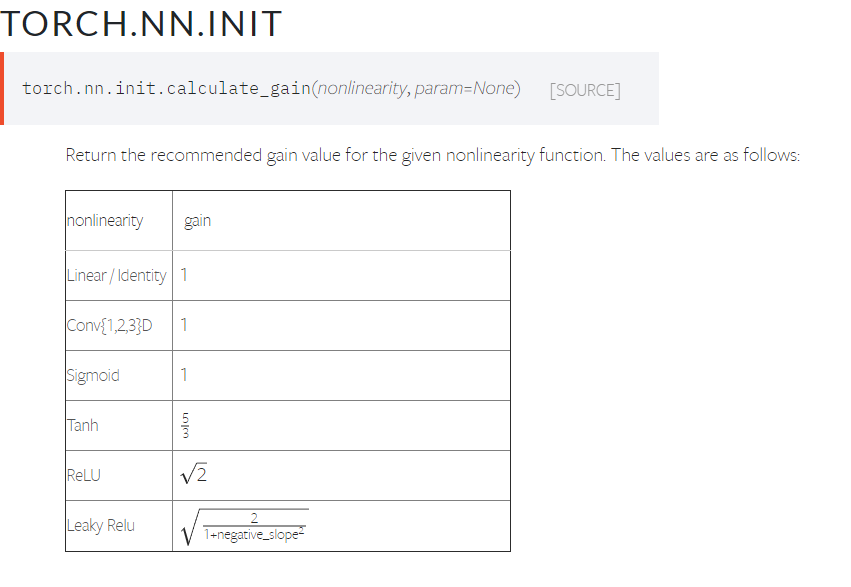
The gain is a scaling factor for some init functions, e.g. xavier init.
It’s used to scale the standard deviation with respect to the applied non-linearity.
Since the non-linearity will affect the std dev of the activation, you might run into some issues, e.g. vanishing gradients. The gain with respect to the non-linearity should give you “good” statistics of your activations.

It’s basically the number of input and output activations.
For a linear layer layer it would be just fan_in = in_features and fan_out = out_features:
print(torch.nn.init._calculate_fan_in_and_fan_out(nn.Linear(10, 2).weight))
In the case of nn.Conv2d it’s a bit more complicated, as you need to calculate receptive field using the kernel size, the in_channels, and number of filters:
print(torch.nn.init._calculate_fan_in_and_fan_out(nn.Conv2d(3, 1, 3, 1, 1).weight))
You can find the formula here.
3 Likes
so if i initiate the weight of a conv2d or conv3d i will use gain=1
if i am right then
- where’s the use of relu or thanh gain value as these functions have no weight to initialize ?
- or i will multiply gain value of conv2d and relu (1*sqrt(2)) for this case bellow
F.relu(self.conv2d()) (just i think this)
am i right?
You are right, that most activation functions don’t have parameters, so that you don’t have to initialize them.
However, you use the gain corresponding to the non-linearity you’ve used in your model.
E.g. for a model like conv -> relu -> conv -> relu, you could use:
nn.init.xavier_uniform_(m, gain=nn.init.calculate_gain('relu'))
to initialize the weights of the conv layers.
4 Likes
Hey btrblck - sorry for replying to this old thread, but do you know any reference on how the gains are calculated? I couldn’t find it anywhere in the code base
Hi Donny, do you have any idea now? I’m just thinking of this question now
I think we can do experiments to test and get the result (the constant) using this code, here the example is tanh():
x = torch.randn(10000)
out = torch.tanh(x)
gain = x.std() / out.std()
print('gain:{}'.format(gain))
hey zihao - excuse my slow reply.
i used the following references to find out where the formula came from more or less https://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf, https://arxiv.org/pdf/1502.01852.pdf.
your estimation does not work for all cases. for example for relu, the post activation value y will be a noncentered variable, and then if you multiply by a weight matrix with \sigma_w, it’s variance will be var(w) (var(y) + mean(y)^2), which will need to be accounted for, and you have no way of knowing what E(y) will be, as its value depends on the layer. Hence your way of estimation will not work for every layer, this contradicts the fact that information gain is applied uniformly across all layers.
As a result, I recommend reading the papers (section 4.2 and 2.2 respectively) as they derive and explain how they come up with the scaling factor which is information gain here quite well
3 Likes
Thank you Donny, that helps a lot !
What is the expected gain for the exponent activation function? Also, I am curious to understand how gain is calculated to begin with?
When browsing others’ code on GitHub, I noticed that most people don’t pass the gain parameter when using Xavier or Kaiming initialization functions, yet the models still converge normally. Does this mean that specifying the gain parameter using the calculate_gain function is a best practice, but not strictly necessary?