I am not sure if anyone can help to answer this here but I cannot seems to be able to find an answer from anywhere:
what exactly is the difference between “token” and a “special token”?
I understand the following:
- what is a typical token
- what is a typical special token: MASK, UNK, SEP, etc
- when do you add a token (when you want to expand your vocab)
What I don’t understand is, under what kind of capacity will you want to create a new special token, any examples what we need it for and when we want to create a special token other than those default special tokens? If an example uses a special token, why can’t a normal token achieve the same objective?
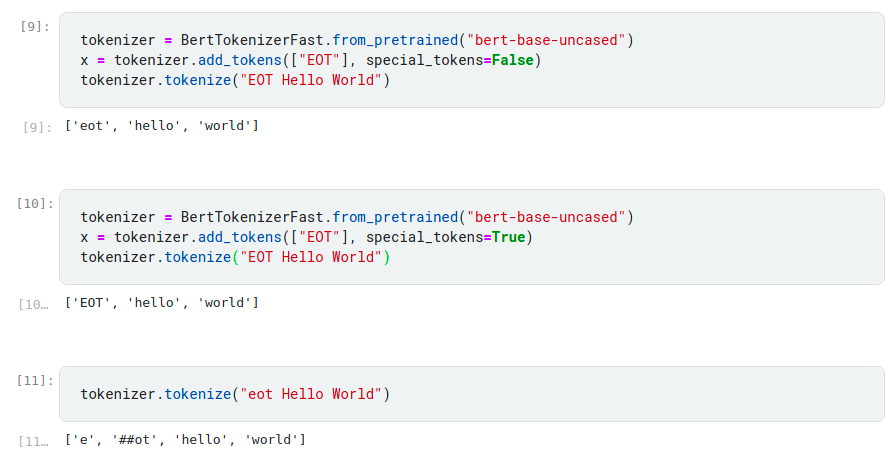
tokenizer.add_tokens(['[EOT]'], special_tokens=True)
And I also dont quite understand the following description in the source documentation.
what difference does it do to our model if we set add_special_tokens to False?
add_special_tokens (bool, optional, defaults to True) — Whether or not to encode the sequences with the special tokens relative to their model.