I am working on a loss regularization term which looks like this: 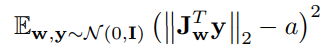 and by taking advantage of this identity
and by taking advantage of this identity
![]() , I implement the loss as follows(y is my noise, w is my latent, fake image is my g(w)).
, I implement the loss as follows(y is my noise, w is my latent, fake image is my g(w)).
std::vectortorch::Tensor g_path_regularize(const torch::Tensor& fake_img, const torch::Tensor&
latents, const torch::Tensor& mean_path_length, Scalar decay=0.01){
std::vectortorch::Tensor res;
auto noise = torch::randn_like(fake_img) / sqrt(
fake_img.size(2) * fake_img.size(3)
);
auto grad = torch::autograd::grad(
{(fake_img * noise).sum()}, {latents}, {}, true, true)[0];
auto path_lengths = torch::sqrt(torch::mean(torch::sum(torch::mul(grad, grad), 2),1));
auto path_mean = mean_path_length + decay * (path_lengths.mean() - mean_path_length);//tensor
auto path_penalty = torch::mean(torch::mul(path_lengths - path_mean, path_lengths - path_mean) );
res={path_penalty, path_mean.detach(), path_lengths};
return res;
}
And in the training process, i have a backward step on my loss regularization term and that can take a relative long time. I wonder if there are better way to implement this. Thanks!