I am using the onecyclelr along with mixed precision training
model = SwinNet().to(params['device'])
criterion = nn.BCEWithLogitsLoss().to(params['device'])
optimizer = torch.optim.AdamW(model.parameters(), lr=params['lr'])
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer,
2e-3,
epochs=5,
steps_per_epoch=len(train_loader)
)
def train(dataloader, model, criterion, optimizer, epoch, params):
model.train()
scaler = torch.cuda.amp.GradScaler() # enable mixed precision training
stream = tqdm(dataloader)
train_loss = 0
for i, (images, target) in enumerate(stream, start=1):
images = images.to(params['device'], non_blocking=True)
target = target.to(params['device'], non_blocking=True).float().view(-1, 1)
images, targets_a, targets_b, lam = mixup_data(images, target.view(-1, 1))
with torch.cuda.amp.autocast(): # wrapper for mixed precision training
output = model(images).to(params['device'])
loss = mixup_criterion(criterion, output, targets_a, targets_b, lam)
train_loss += loss
optimizer.zero_grad(set_to_none=True)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.step(scheduler)
scaler.update()
train_loss /= len(dataloader)
return train_loss
I am getting the following error:
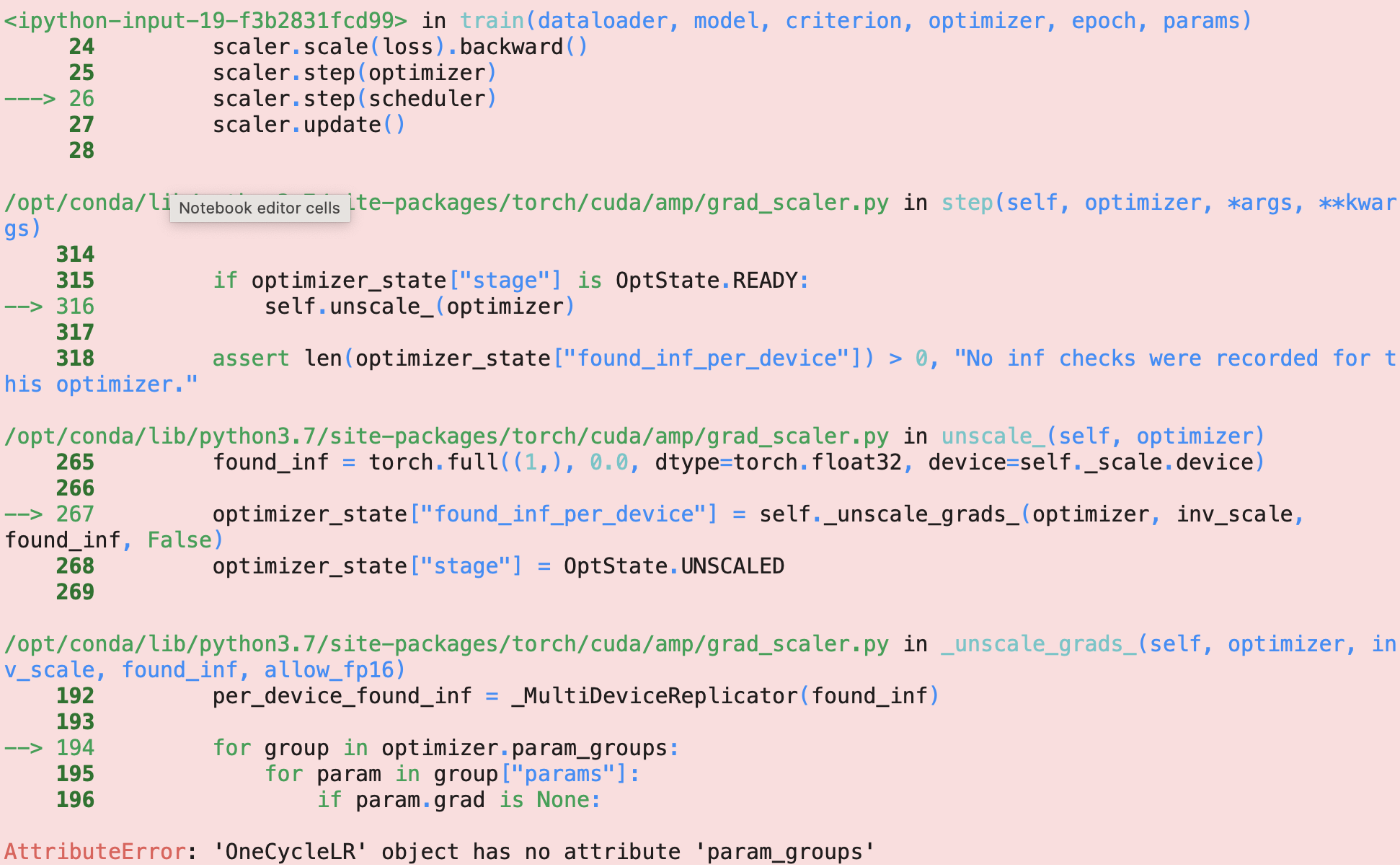
What is the correct way to implement mixed precision along with onecyclelr ?