Hi
I’d like to know: what is the difference between “Tensor A = B” and “Tensor A.set_data(B)” in LibTorch?
I found that when I try to change the value of a model’s(networks’) parameter tensor, I could only use A.set_data(B) rather than A = B.
And using A.set_data(B) will lead to an error when execute the .backward() method.
set_data will shallow-copy all non-autograd TensorImpl fields and will not bump the version counter, if I’m not mistaken. I think the equivalent would be an assignment to the .data attribute in Python, which is not recommended as it might yield unwanted side effects.
The Tensor A = B; operation will create a new tensor pointing to B and should not yield any side effects.
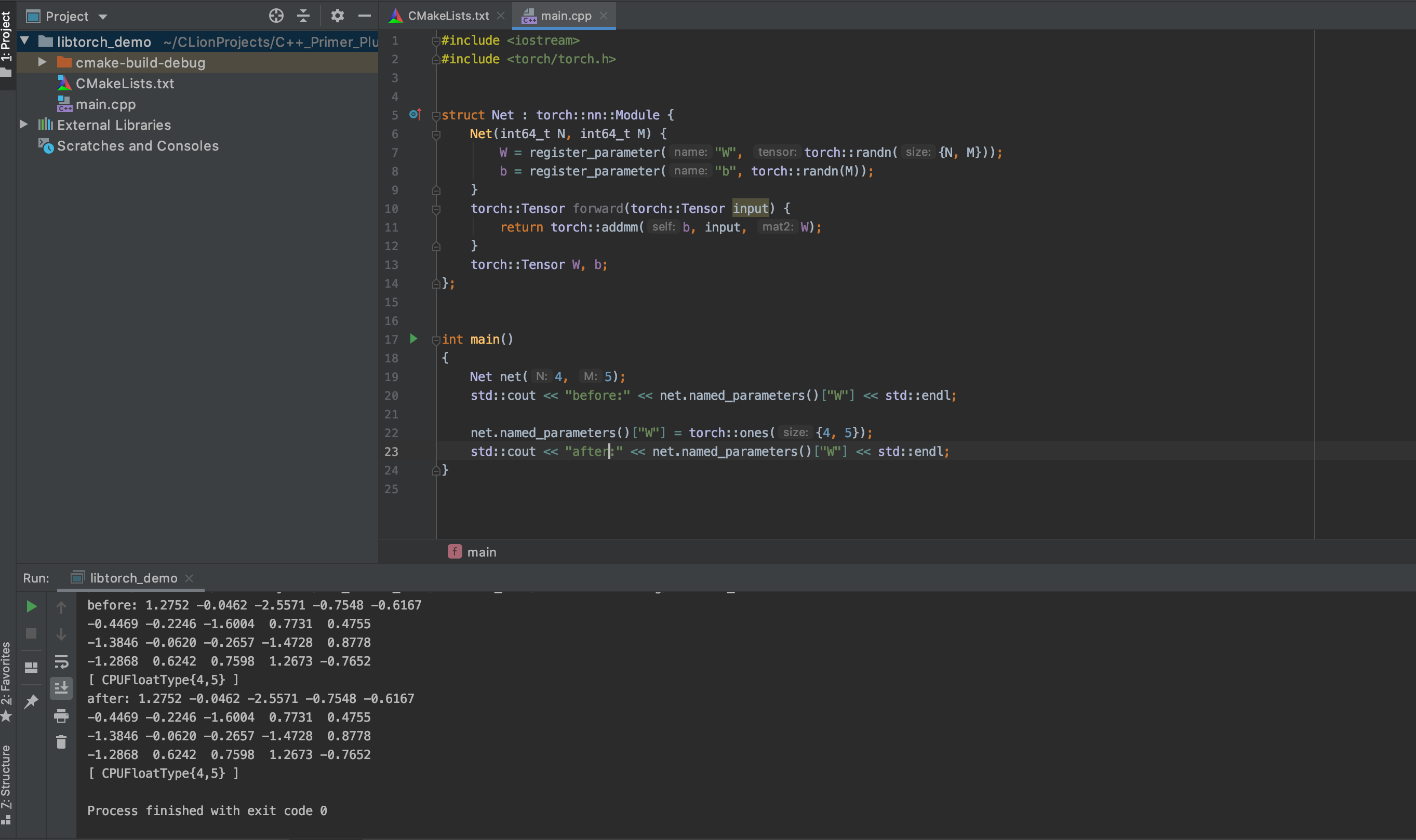
Thanks for the reply. Strange! When I use “model.named_parameters[“name”] = a_tensor” to change some parameters of the model, it seems that it doesn’t work, so I have to use .set_data() instead of it. Is there any solutions for this?
I don’t think your code would work, as you would have to call the named_parameters method as:
model.named_parameters()["key"]
Yes, I think this is expected as in the Python frontend, as you would need to copy the data into the parameters directly using this workflow.
I assume you are getting errors from Autograd? If so, use at::NoGradGuard guard; to make sure Autograd doesn’t track these copies in the current scope.
Sorry, I made a typo there. My “error” is that after I execute the “model.named_parameters()[“key”] = some_tensor” , the parameters tensor is the same as before: