If I have the following code snippet:
kernel1(xxx)
....other cpu code...
torch.cuda.nvtx.push_range("marker")
....other cpu code...
In the Nsight Systems GUI, does the time from the end of kernel1 in CUDA API to the start of the “marker” in the NVTX represent the execution time of the “other cpu code” even if I do not set CUDA_LAUNCH_BLOCKING=1 ?
My guess is that since the CUDA API line represents the CPU-side activity of kernel launches and the execution on the CPU is synchronous, the answer to the above question is “yes.”
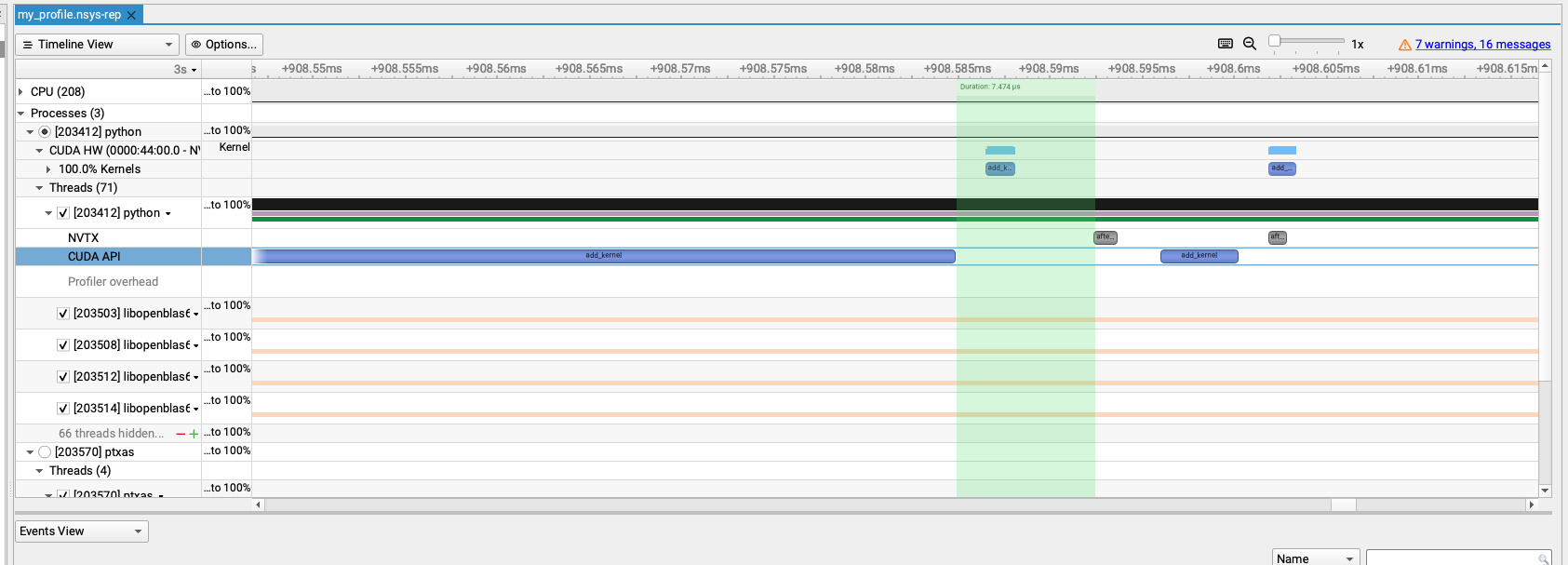
If the graph displayed in the Nsight Systems GUI looks like the following image (note that CUDA_LAUNCH_BLOCKING was not set during the nsys profiling), and the code being run is:
add_kernel(xxx)
print("hello")
print("hello")
torch.cuda.nvtx.range_push("after add_kernel")
Then the 7.474us shown in the graph is the time required for the two print statements, and it is also the time from when the CPU has launched the add_kernel to when it has executed the range_push, correct?