A. ENV
1. libtorch 1.8.1 CPU version
2. centos 7
3. Linux localhost.localdomain 3.10.0-693.el7.x86_64 #1 SMP Tue Aug 22 21:09:27 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
4. gcc version 9.3.1 20200408 (Red Hat 9.3.1-2) (GCC)
5. x86_64 4 CPU
B. TEST CODE
torch::jit::script::Module module;
module = torch::jit::load(argv[1]);
std::vectortorch::jit::IValue inputs;
at::Tensor input = torch::ones({1, 300, 40});
inputs.push_back(input);
torch::NoGradGuard guard;
at::set_num_interop_threads(1);
at::set_num_threads(1);
// record profile
torch::autograd::profiler::RecordProfile perf_guard(argv[2]);
for (int i=0; i < num; i++) {
b = time_get_ms();
std::cout << "module forward begin" << std::endl;
at::Tensor output = module.forward(inputs).toTensor();
e = time_get_ms();
d = e - b;
std::cout << "forward output size : " << output.numel() << ", No." << i <<" forward time : " << d << std::endl;
total_duration = total_duration + d;
}
avg_duration = total_duration / num ;
std::cout << "AVG forward time : " << avg_duration << std::endl;
C. LATENCY
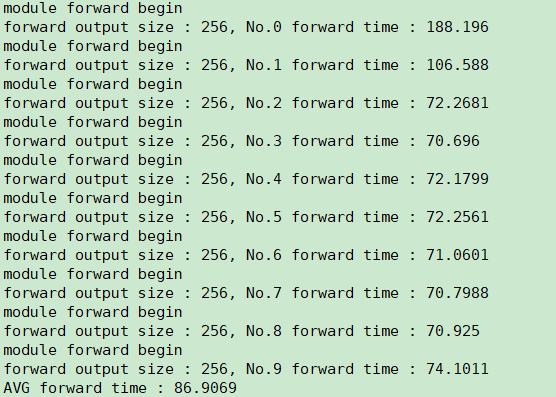
See the comments for specific data .
- No.0 forward duration : 188.196 ms;
- No.1 forward duration : 106.588 ms;
- No.2 ~ No.9 forward duration : about 70 ms;
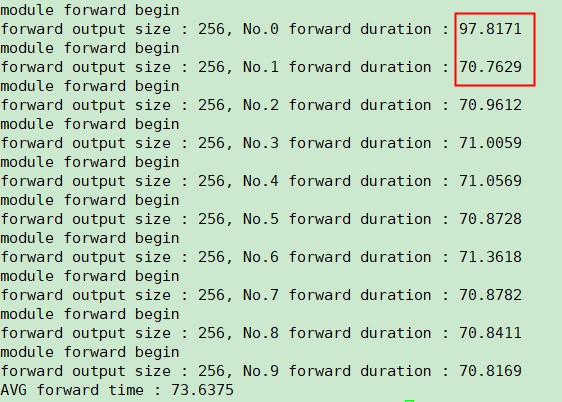
D. PERFORMANCE
E. QUESTION
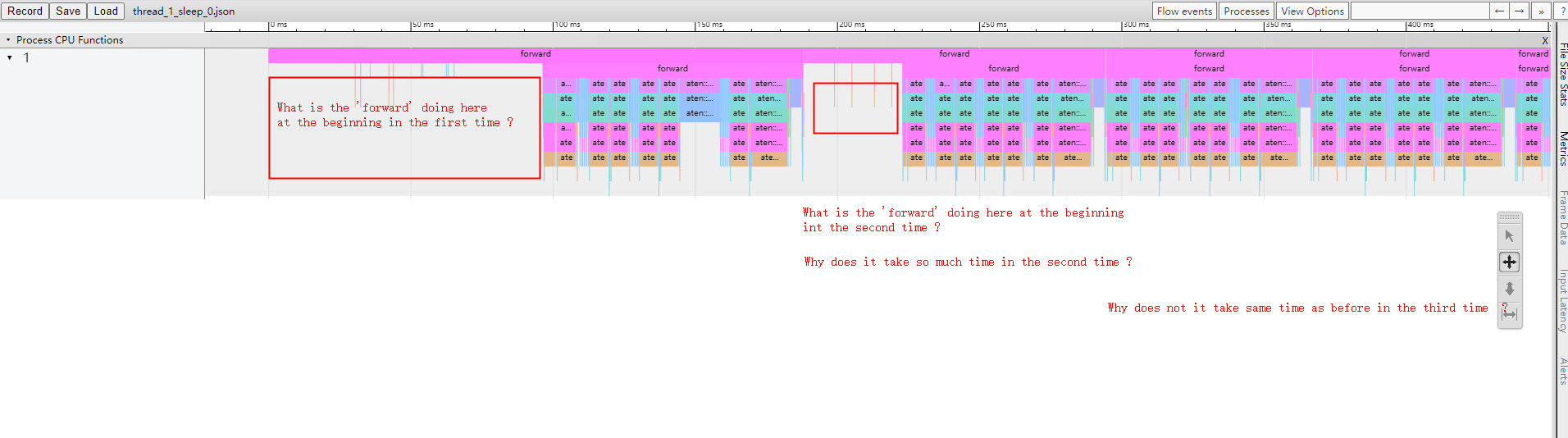
- what is the ‘module.forward’ function is doing at the beginning ?
- I guess when run ‘module.forward’ function in the first time, the ‘module.forward’ function may do something about warming up or else ?
- If preheating is needed during the first ‘module.forward’ running? Why does the function spend so much time at the beginning of the second run? But in the subsequent run, it did not take the same time ?