Hi,
I have a noob question about the behavior of BCEWithLogitsLoss. I tested its loss with some data
.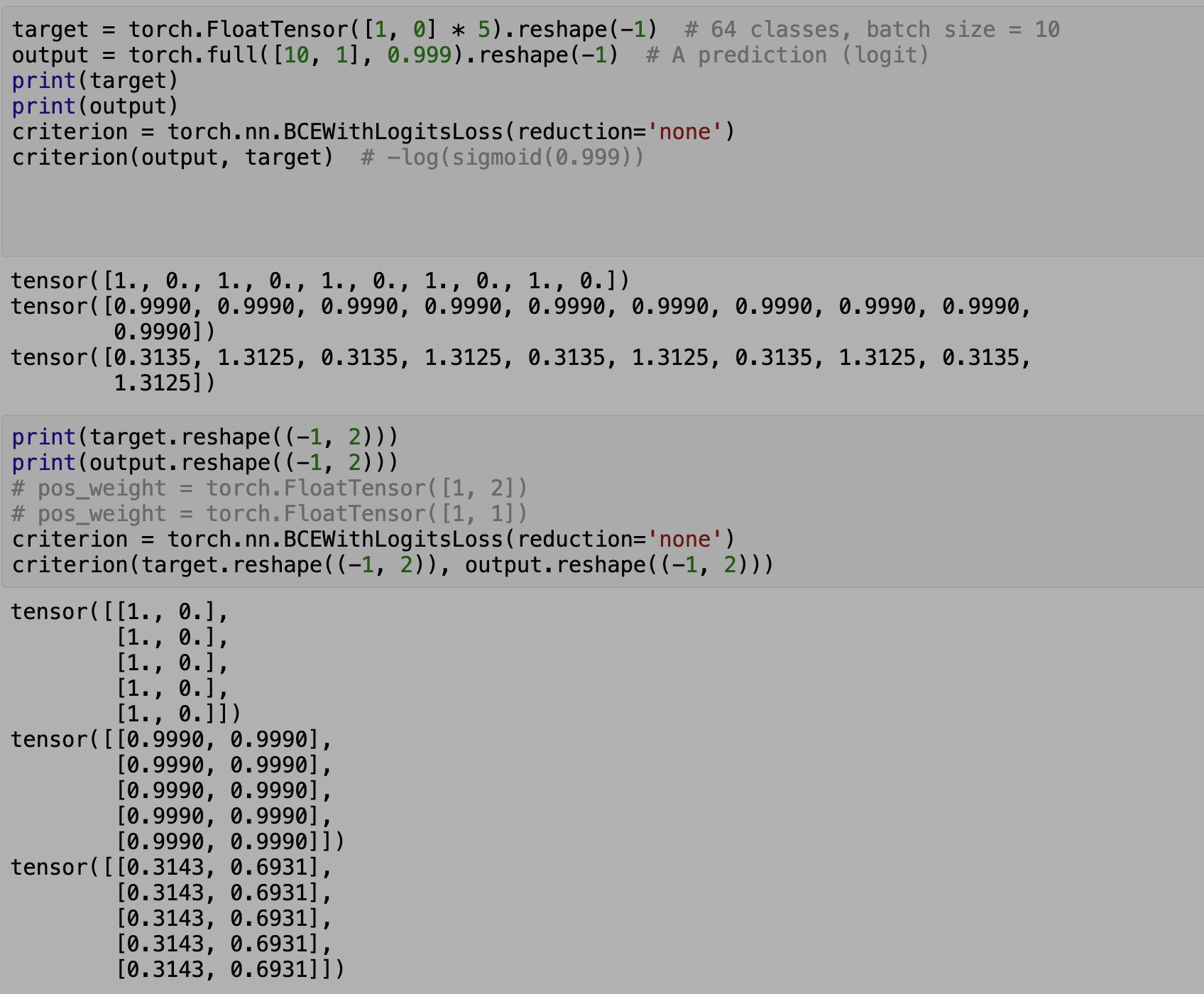
My understanding is that the loss between 0.999(x) and 1(y) should be 0.3135 and loss between 0.999(x) and 0(y) 1.3125. Thats the case when target and output are of size(1, #sample), which is binary classification. However, when I reshape the data to size(#size, #class) to simulate multi-label, the loss is different (0.3143, 0.6931).
So how will BCEWithLogitsLoss calculate loss for multilabel. My understanding for the doc is they should be the same. Thank you!
