I found that use batch size = 1 and do not pad is the fastest way to inference, is this conclusion correct? the best practice is do not batch and pad ?
Well, if your batch size is 1 why pad - you only pad to make sure your data if B X L X D where N is the batch size, L is the max length, and D is the vector dimension - i.e. you pad so you get a tensor? Batches of size 18 would I guess take a longer time than batches of size 1, in general. However, typically have Predict Time(batch of size 18) <<< 18*Predict Time(batch of size 1), so this is why batching helps.
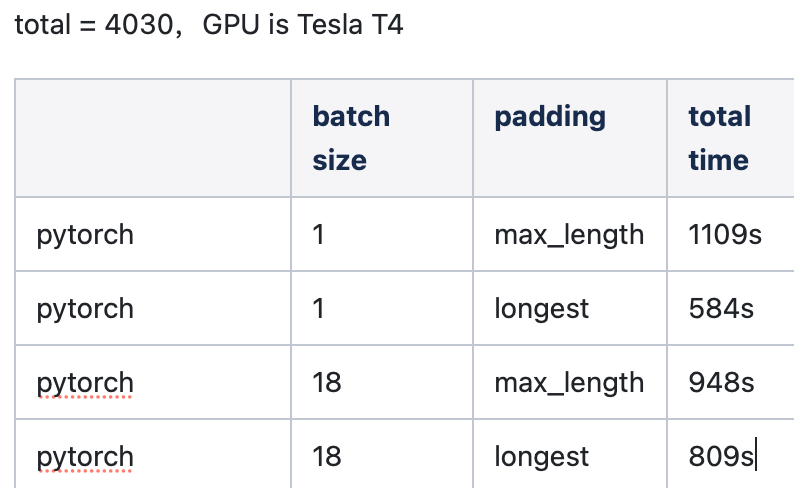
when batch size is 1, longest padding is same with do not pad. In my experiment, I found that after processing 4030 data, the total time of batch=1 is much less than that of batch=18, which is why I think batching is useless.
Maybe this is due to the GPU but this is still surprising to me. In the case when you have batch 1, why do you need to pad? You are saying 1 predict is 584 s and a batch of size 18 is 948 s if you pad each sequence using the maximum length sequence in the batch? But then, your average predict time for the 18 case is 984 s / 18 no? That’s less than 584 s … Is this the right way to interpret the table? Let me know if I’m missing something …
the total time is the time costs of processing 4030 items, so the average predict time of batch=1 and do not pad is 584 / 4030 seconds, and the average predict time of batch=18 and longest padding is 809 / 4030 seconds