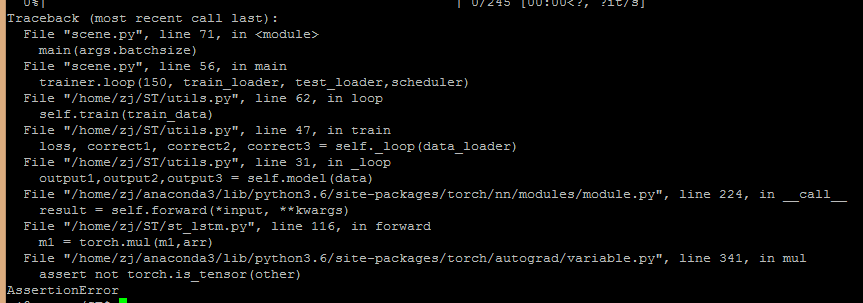
We want to realize a net that sent the vgg features into the lstm, then generate a tensor (2,3) and a fc layer for classification. For the generated (2,3) tensor, we want some elements to be 0. So we use the tensor arr to element-wise multiplication with m1. And then the m1 continue to be sent to the next .
What’s wrong with me in the process of forward?
How to realize the element-wise multiplication in the forward?
Another question ,I want to make my own loss function that need to use the element of m1,m2,m3. How can i get the element from the tensor to make my loss function.
class ST_LSTM(nn.Module):
def __init__(self,features,num_classes):
super(ST_LSTM,self).__init__()
self.features = features
for p in self.features.parameters():
p.requires_grad=False
self.classifier2 = nn.Sequential(
nn.Linear(1024, 1024),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(1024, 30),
)
self.mm = nn.Sequential(
nn.Linear(1024, 512),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 6),
)
self.lstm = nn.LSTM(7*7*512,1024,batch_first=True)
# stn is the Spatial Transformer Networks from the pytorch Tutorial
def stn(self, x, theta):
# x = self.features(x)
# xs = self.localization(x)
# xs = xs.view(-1, 10 * 3 * 3)
# theta = self.fc_loc(xs)
# theta = theta.view(-1, 2, 3)
grid = F.affine_grid(theta, x.size())
x = F.grid_sample(x, grid)
return x
def forward(self, x):
y =self.features(x)
# z1 = self.stn(x)
z1= y.view(-1,1,7*7*512)
r1, (h1, c1) = self.lstm(z1)
s1 = self.classifier2(r1[:,-1,:])
m1 = self.mm(r1[:,-1,:])
m1 = m1.view(-1,2,3)
arr = torch.cuda.FloatTensor([1, 0, 1, 0, 1, 1])
# arr = np.array([1,0,1,0,1,1])
# arr = torch.from_numpy(arr)
# 16 is batchsize we want to make a tensor(batchsize,2,3) to element-wise mul with m1
arr = arr.repeat(16,1)
arr = arr.view(16,2,3)
m1 = torch.mul(m1,arr)
z2 = self.stn(y,m1)
z2 = z2.view(-1,1,7*7*512)
r2, (h2, c2) = self.lstm(z2,(h1,c1))
s2 = self.classifier2(r2[:,-1,:])
m2 = self.mm(r2[:,-1,:])
m2 = m2.view(-1,2,3)
z3 = self.stn(y,m2)
z3 = z3.view(-1,1,7*7*512)
r3, (h3, c3) = self.lstm(z3,(h2,c2))
s3 = self.classifier2(r3[:,-1,:])
return s1,s2,s3