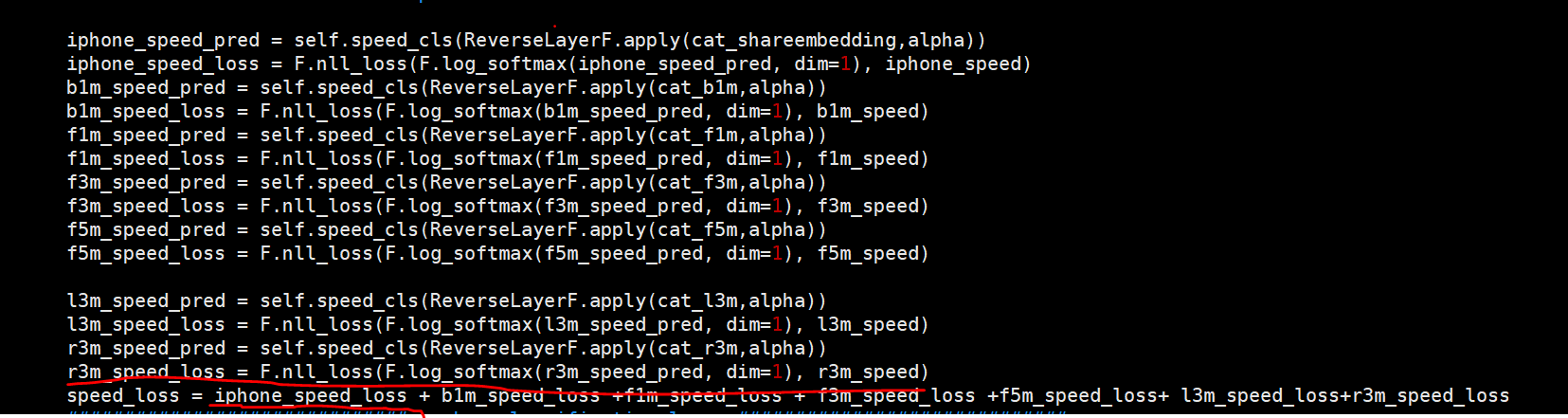
Hi everyone, when I use F.nn_loss() in model forward as above. Then I two GPUs to train the model in form of model = torch.nn.DataParallel(model).cuda(). I get a tuple speed_loss. Before I called loss.backward, I use torch.sum(speed_loss) to get a scalar. Is this right? The tuple is from two gpus calculation. I add them together then go backward directly.
The output of nn.DataParallel should be a single tensor on the default device and thus the target as well.
I’m not sure, if you are using a custom data parallel approach, but if you are calculating the loss based on the model output and target, you should get a tensor (also on the default device) and not a tuple.
Thanks very much, I fixed it.
I got the same problem, getting multiple loss. How do you solve that? Thanks a lot!
OK…I fixed that. If you compute and return the loss inside the model, then you will get a loss list. Just average the loss list.